The year is coming to an end, and Databend is about to enter its third year. Before we count down the new year, it's a good idea to look back and see how Databend did in 2022.
Open Source: Receiving Increased Attention
Databend is a powerful cloud data warehouse. Built for elasticity and efficiency. Free and open. Also available in the cloud: https://app.databend.com .

The open-source philosophy has guided Databend from the very beginning. The entire team works seamlessly on GitHub where the Rust community and many data pros are fully involved. In 2022, the Databend repository:
- Got 2,000+ stars, totaling 5,000 .
- Merged 2,400+ PRs, totaling 5,600 .
- Solved 1,900 issues, totaling 3,000 .
- Received 16,000 commits, totaling 23,000 .
- Attracted more contributors, totaling 138 .
Development: Inspired by Real Scenarios
Databend brought many new features and improvements in 2022 to help customers with their real work scenarios.
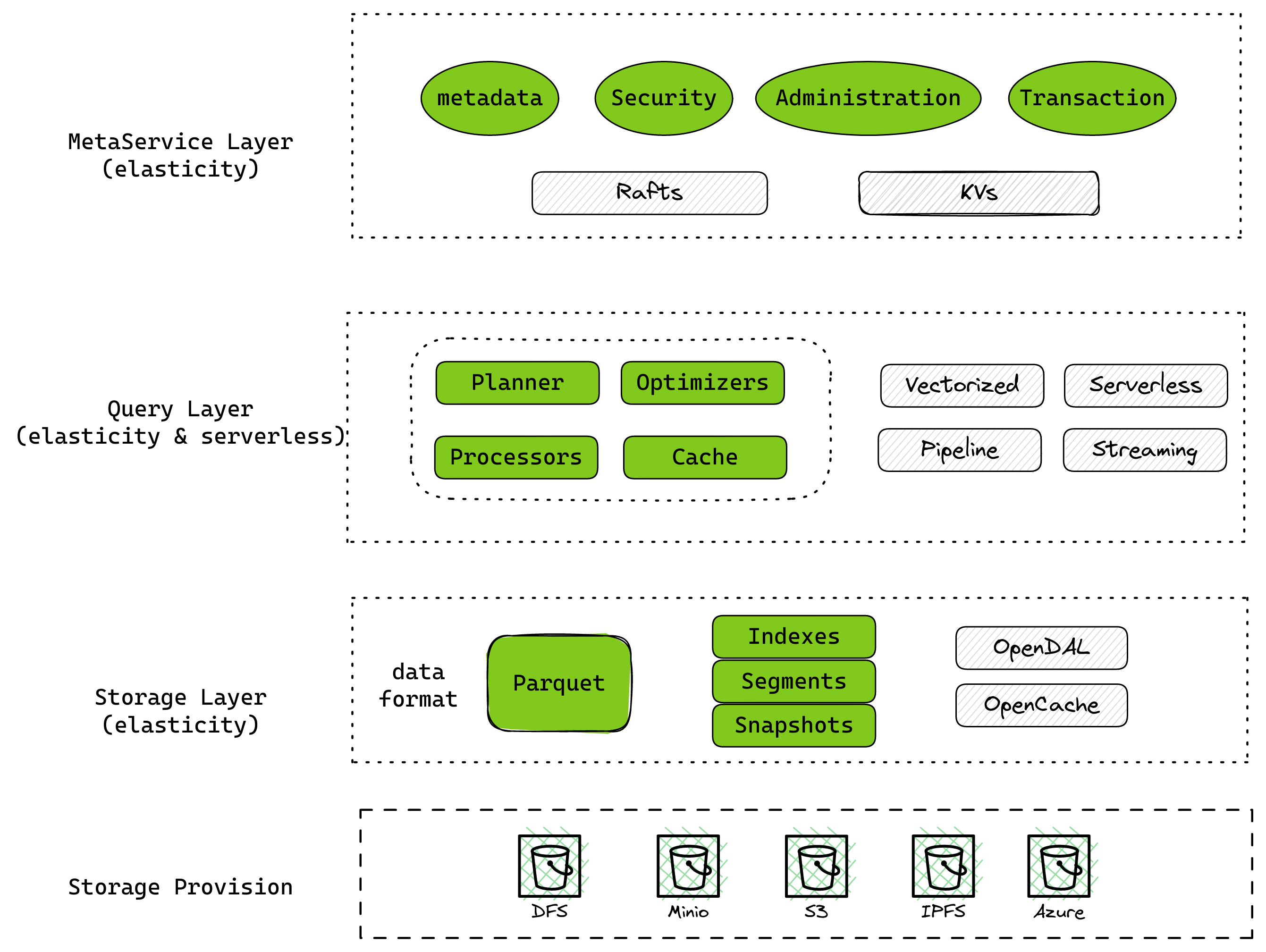
Brand-New Data Warehouse
As a data warehouse inspired by and benchmarking itself against Snowflake and Clickhouse, Databend fully took advantage of "Cloud Native" to bring you a new design and implementation without breaking the balance between performance and maintainability:
- Added support for Stage and Data Sharing, helping users manage their data life cycle with more options.
- Introduced a new planner with user-friendly error prompts and efficient optimization techniques for the execution plan.
- Redesigned the type system to support type checking and type-safe downward casting.
- Enhanced the new processor framework: It can now work in both Pull and Push modes.
- Added experimental support for Native Format to improve performance when running on a local disk.
Databend as Lakehouse
Storing and managing massive data is key to our vision "Databend as Lakehouse" . A lot of efforts have been made in 2022 for a larger data payload and a wider range of accepted data sources:
- Adopted OpenDAL in the data access layer as a unified interface.
- Expanded support for structured and semi-structured data.
- Added the ability to keep multiple catalogs: This makes integrations with custom catalogs such as Hive much easier.
- Added the ability to query data directly from a local, staged, or remote file.
Optimal Efficiency Ratio
After a year of continuous tuning, we brought Databend to a new stage featuring elastic scheduling and separating storage from compute. We're thrilled to see a significant improvement in the efficiency ratio:
- In some scenarios, Databend works as efficiently as Clickhouse.
- Lowered costs by 90% compared to Elasticsearch, and by 30% compared to Clickhouse.
Testing: Put Us at Ease
Comprehensive tests help make a database management system robust. While optimizing performance, we also care about the accuracy and reproducibility of SQL results returned from Databend.
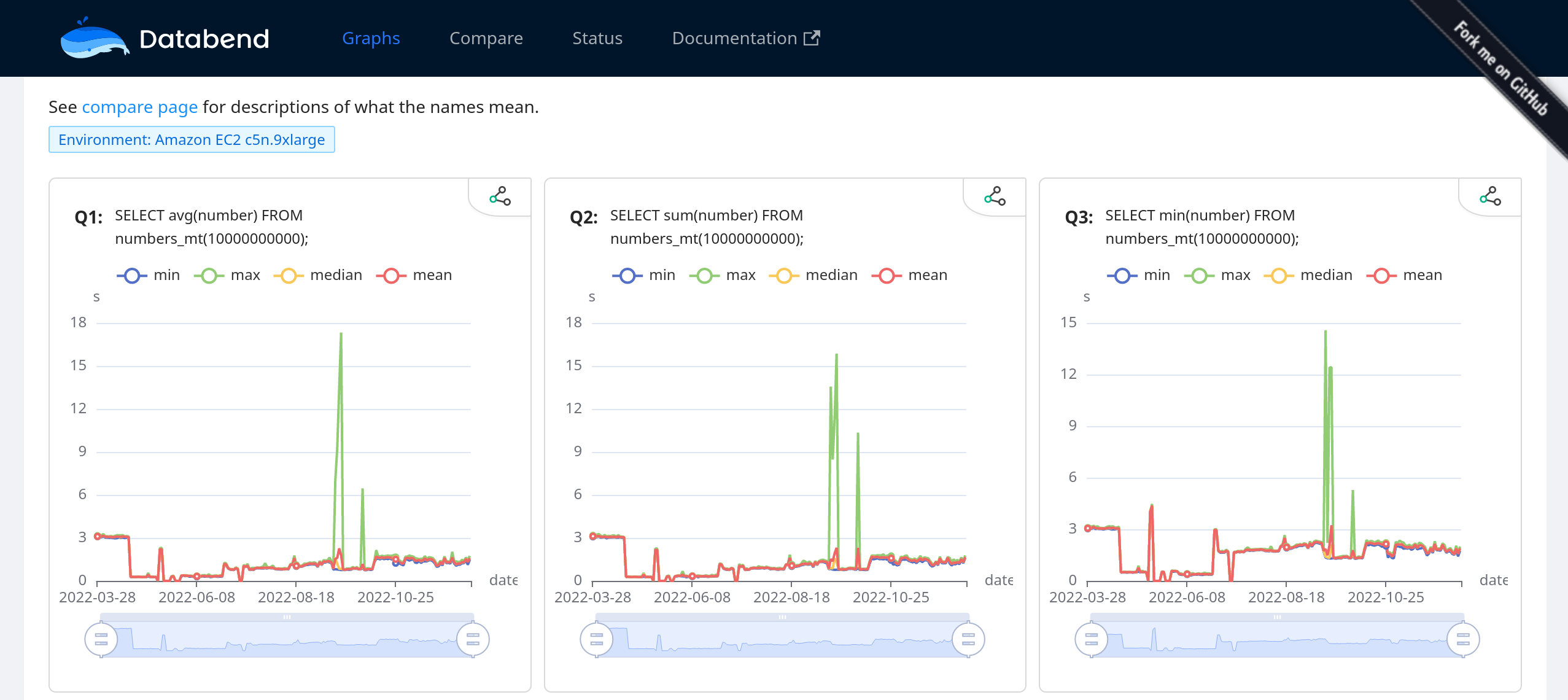
Correctness Testing
In 2022, we replaced stateless tests with SQL Logic Tests for Databend in the first place. We also migrated a large number of mature test cases to cover as many scenarios as possible. Afterward, we started to use a Rust native test program called sqllogictest-rs instead of the previous Python one, which saved us a lot of time on CI without losing the maintainability of the tests.
Furthermore, we also planned and implemented three types of automated testing (TLP, QPS, and NoREC) supported by SQLancer. All of them have been successfully merged into the main branch with dozens of bug fixes.
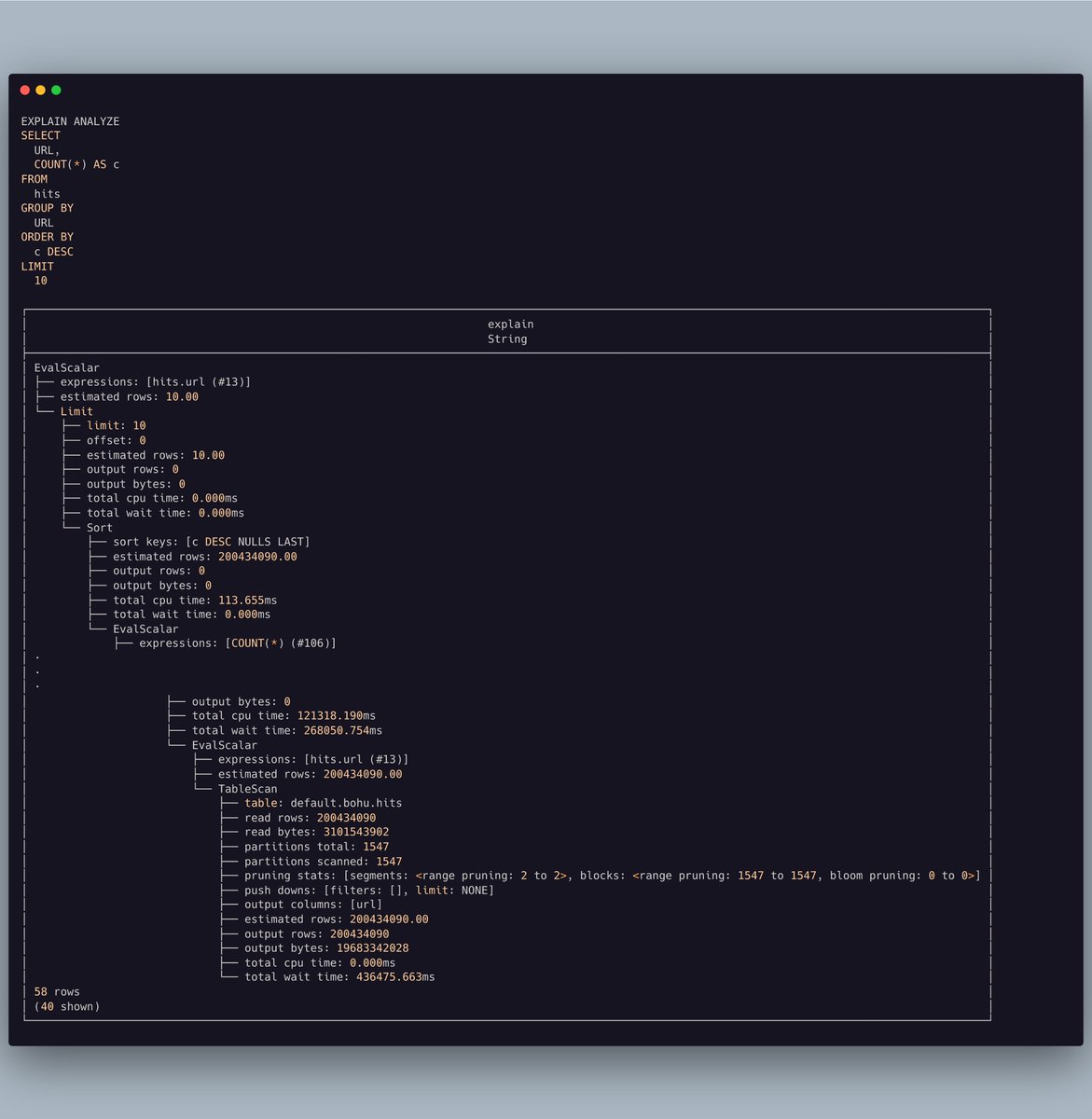
Performance testing is also essential for us. In 2022, we launched a website (https://perf.databend.rs/) to track daily performance changes and spot potential issues. Meanwhile, we actively evaluated Databend against Clickbench and some other benchmarks.
Ecosystem: Give and Take
The Databend ecosystem and users benefit from each other. More and more users were attracted to the ecosystem and joined the community in 2022. As they brought their own creative ideas to Databend and made them come true, the Databend ecosystem made tremendous progress and started to flourish in the field.
Positive Expansion
We build and value the Databend ecosystem. Databend is now compatible with the MySQL protocol and Clickhouse HTTP Handler, and can seamlessly integrate with the following data services or utilities:
- Airbyte
- DBT
- Addax (Datax)
- Vector
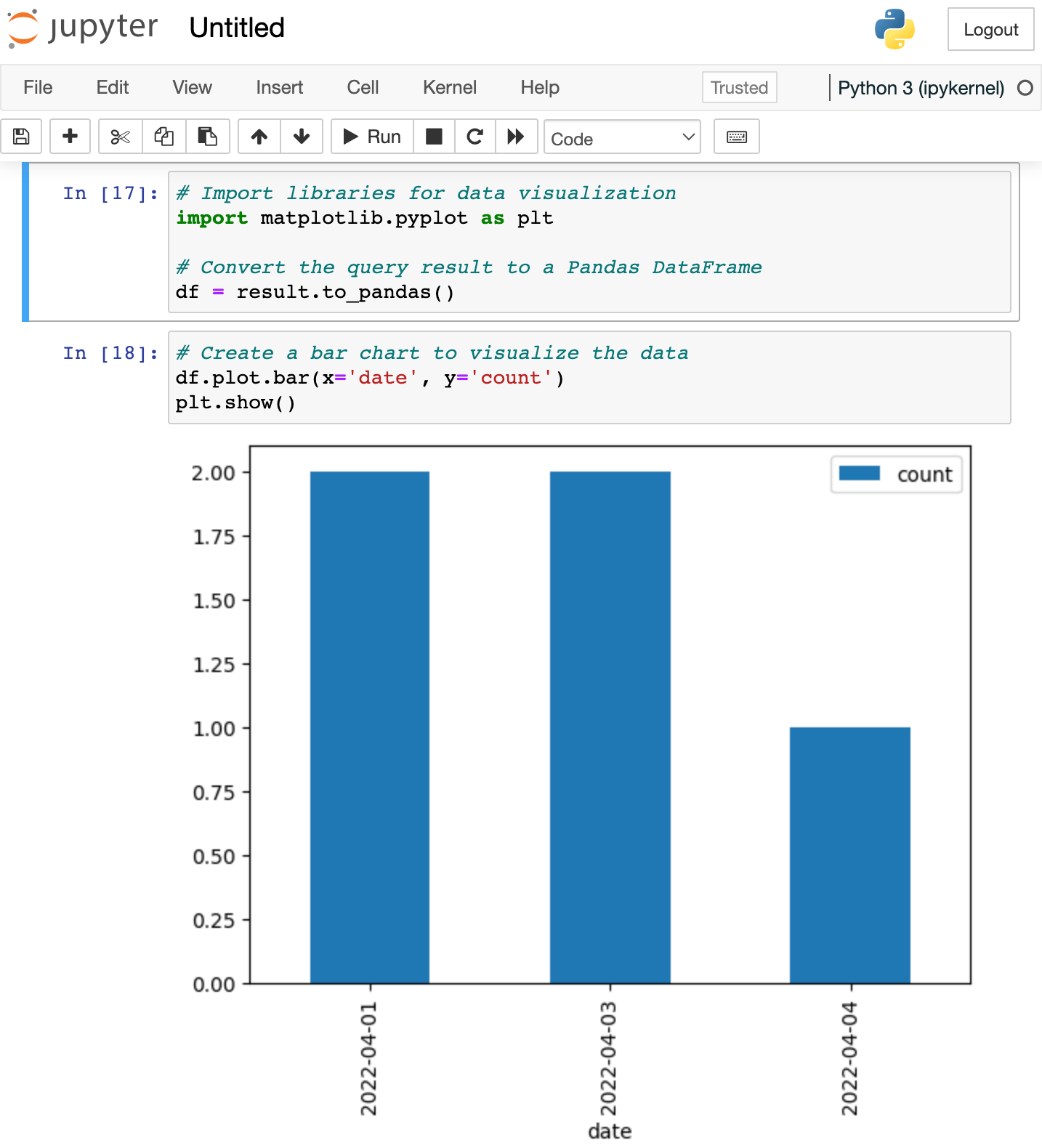
- Jupyter Notebook
- DBeaver
To help users develop and customize services based on Databend, we developed drivers in multiple languages, including Python and Go.
Growing with Users
Users are the basis of Databend. They help develop Databend and stir up the whole community.
In 2022, Databend added support for the Hive Catalog with the help of Kuaishou Technology. This connected Databend to the Hive ecosystem and encouraged us to consider the possibility of multiple catalogs. DMALL implemented and verified data archiving with Databend. We also appreciate SHAREit, Voyance, DigiFinex, and Weimob for their trust and support.
The Databend ecosystem includes a few projects that are loved and trusted by other products:
- OpenDAL now manages the data access layer for sccache , which provides further support for Firefox CI . Other database and data analysis projects, such as GreptimeDB and deepeth/mars , also used OpenDAL for data access.
- OpenRaft was used to implement a Feature Registry (database to hold feature metadata) in Azure/Feathr. SAP, Huobi, and Meituan also used it in a few internal projects.
- The MySQL protocol implementation in OpenSrv has been applied to multiple database projects such as GreptimeDB and CeresDB .
Knowledge Sharing
In 2022, the Databend community launched the "Data Infra Club" for knowledge sharing. Our friends from PingCAP, Kuaishou Technology, DMALL, and SHAREit were invited to share their insights on big data platforms, Data Mesh, and Modern Data Stack. You can find all the video replays on Bilibili if you're interested.
Going Cloud: Sky's the Limit
Going cloud is part of Databend's business strategy where most Databend users come from the cloud.
Built on top of Databend, Databend Cloud is a big-data analytics platform of the next generation, featuring easy-to-use , low-cost , and high-performance . Two versions of Databend Cloud are now available and open for trial:
















![mergify[bot]](https://avatars.githubusercontent.com/in/10562?v=4&s=117)











![dependabot[bot]](https://avatars.githubusercontent.com/in/29110?v=4&s=117)















