Databend is a modern, open-source, cloud-native data warehouse. It leverages cost-effective cloud storage as its primary storage solution and delivers fast and efficient analytical performance. Databend has received widespread acclaim for its ability to help numerous customers achieve cost savings and increased efficiency in scenarios such as data warehousing and user behavior logging.
Databend is also available on the cloud! With Databend Cloud, you can host your Databend instances and benefit from a serverless deployment where you are billed based on compute duration rather than hardware resources. A serverless deployment not only helps lower costs but also enhances system elasticity and reliability. By utilizing Databend Cloud, you can easily build cost-effective and high-performance data warehouses, allowing you to focus on data analysis rather than maintenance work.
Databend Cloud and Databend were almost simultaneously launched for development. The development of Databend Cloud involves requirements for infrastructure scalability, high availability, etc., which align with Databend's cloud-centric positioning. The continuous refinement of both Databend Cloud and Databend has made Databend Cloud more user-friendly while also making Databend easier to deploy, manage, and access.
Efficiently, securely, and cost-effectively utilizing cloud resources has become a common focus in the industry. This article will introduce the design and trade-offs of the Databend Cloud architecture, as well as the work mechanism of its various components. We hope that this article will help you better understand the advantages of the cloud, making your cloud-based data warehouse more cost-effective, efficient, secure, and user-friendly.
Design Principles
The following principles are integrated throughout the development process of Databend Cloud:
- Pay-as-you-go: Minimizing user expenses in computing, storage, and data transfer resources.
- Serverless: Leveraging Kubernetes and Infrastructure as Code (IaC) for automated operations, always using the latest version.
- Security: Following SOC2 standards to design a zero-trust architecture with strong isolation between tenants and default encryption.
- Data ecosystem: Incorporating cloud-native and Rust elements into the big data ecosystem.
The design principles above are interconnected. To minimize resource expenses, we employed a serverless architecture that promptly releases unused resources to avoid incurring unnecessary costs. With Kubernetes and Infrastructure as Code (IaC), we established a standardized infrastructure, enabling built-in security mechanisms across different cloud providers and regions. Additionally, external data systems can seamlessly integrate with Databend Cloud without needing to care about infrastructure details.
Next, we will provide a detailed overview of the Databend Cloud architecture and how the components work together.
Architecture
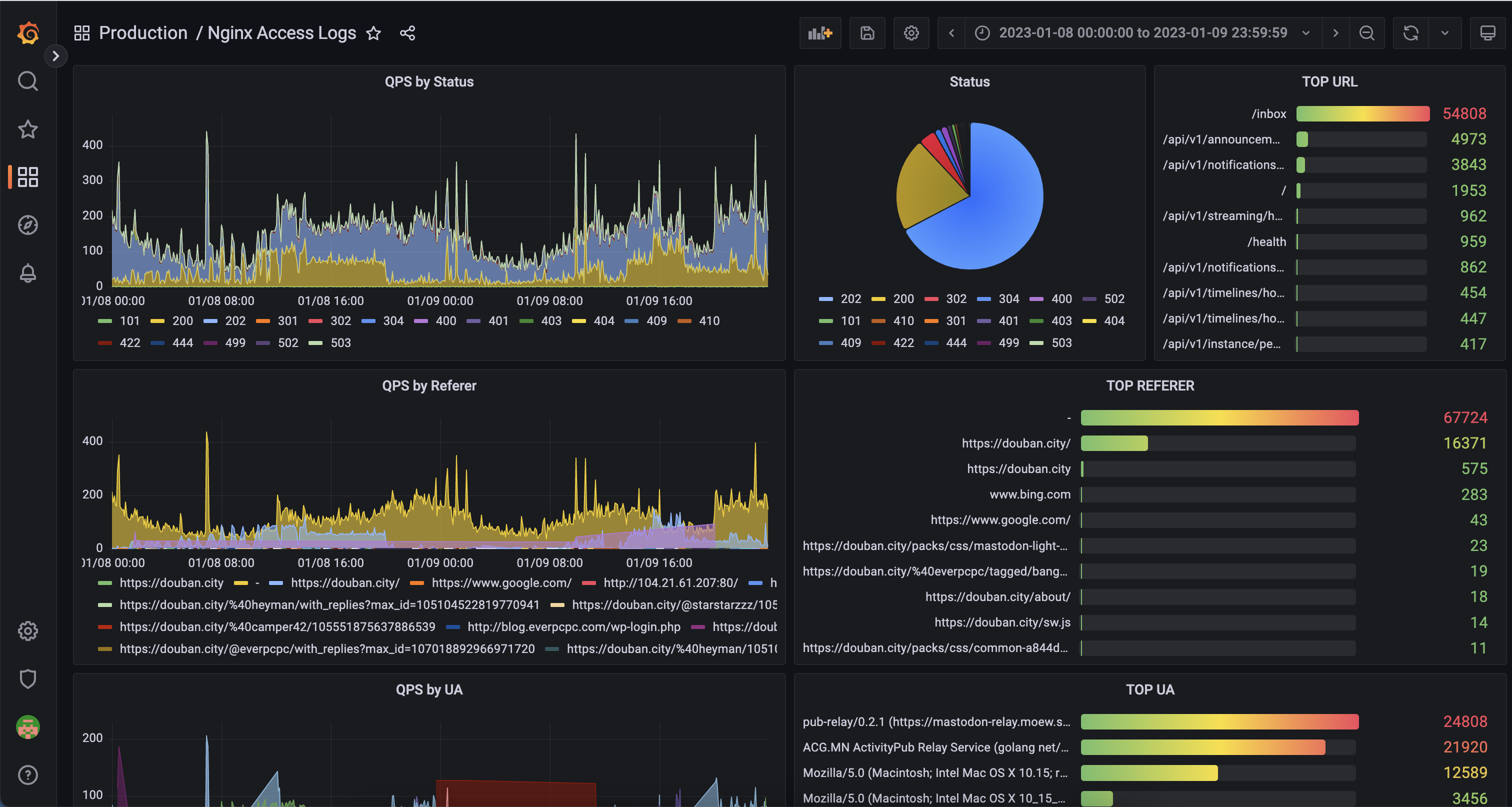
The following is an architectural overview of Databend Cloud within a single region:
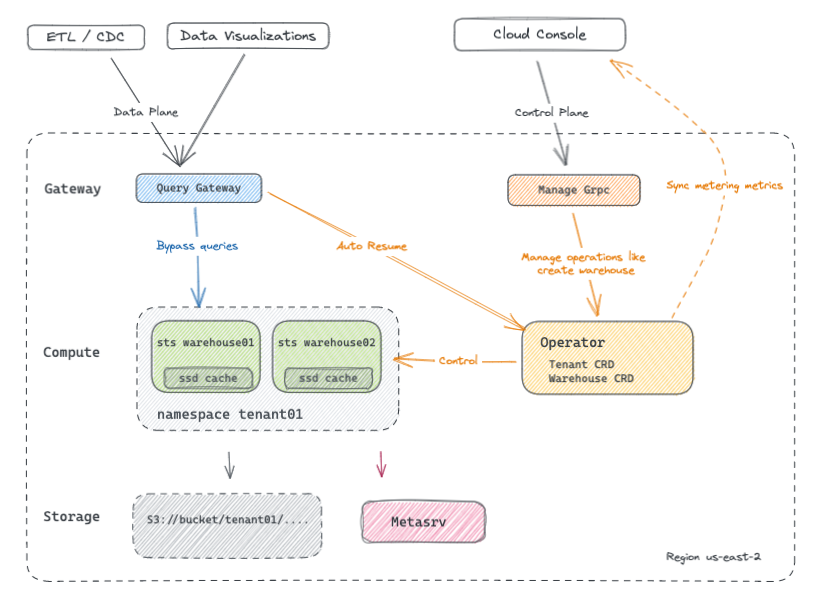
In general, the architecture of Databend Cloud follows a design that separates the control plane from the data plane, with a multi-tenant storage layer and a serverless computing layer:
- Object storage is used as the primary storage, with tenant-level isolation.
- Kubernetes is used to manage computing resources, with Operators serving as the central component of the control plane. Each region exposes an internal Managed gRPC service for cross-cloud management.
- Meta cluster is used for storing table schemas, identity authentication, and other metadata.
- A custom Query Gateway is used as the entry point for the data plane.
- A unified cross-region Cloud Console serves as the management interface for managing accounts, organization information, usage metrics, and more.
Object Storage
Databend utilizes object storage as the primary storage, enabling a completely decoupled architecture of storage and computation from day one. This greatly simplifies the development of cloud products, as it only requires managing and scheduling stateless compute nodes without the need for complex mechanisms such as node state migration or master-slave switching.
However, leveraging object storage also presents new challenges for our query engine:
- Unstable access latency of object storage.
- Potential access limitations imposed by cloud providers.
To address these challenges, we have implemented these optimizations:
- Parallel scanning of object files at a large scale to maximize I/O bandwidth.
- Dynamic scheduling framework that adapts to varying request latencies.
- Dynamic backoff and retry for handling errors related to cloud storage limitations, ensuring query success.
- Addition of local SSD cache to accelerate access to hot data.
Managing Compute Resources with Kubernetes
In Databend Cloud, we utilize Kubernetes to manage the compute layer. Kubernetes allows us to abstract the differences between different cloud providers and use unified APIs to coordinate the scaling of compute resources. The widely adopted Operator development pattern in the Kubernetes community enables us to flexibly extend control logic for operations such as usage statistics and auto-scaling.
Operators are at the core of the control plane. They define two Custom Resource Definitions (CRDs) for managing tenants and warehouses. When a warehouse is created in Databend Cloud, it corresponds to a Warehouse CRD, and the Operator creates a StatefulSet to start the Databend cluster for that warehouse.
Although Databend Query itself is stateless, we choose to use StatefulSet instead of Deployment for managing pods. Firstly, pods in StatefulSet are assigned a fixed ordinal number, and we designate Pod 0 as the coordinator to handle query planning and coordination. Secondly, we bind an SSD cache to the Databend cluster for accelerating data access.
In addition, to improve overall resource utilization, we use Karpenter as a scaler. It dynamically requests more physical resources from cloud providers and automatically adds them to the cluster when physical resources are insufficient, and releases them when usage is low. This enables the Kubernetes cluster to form an elastic resource pool that can adapt to changes in our physical resource requirements.
Databend caches metadata from Metasrv as much as possible to reduce the access pressure on Metasrv. As a result, we choose to deploy Metasrv as a multi-tenant shared cluster, using key prefixes to differentiate metadata for different tenants.
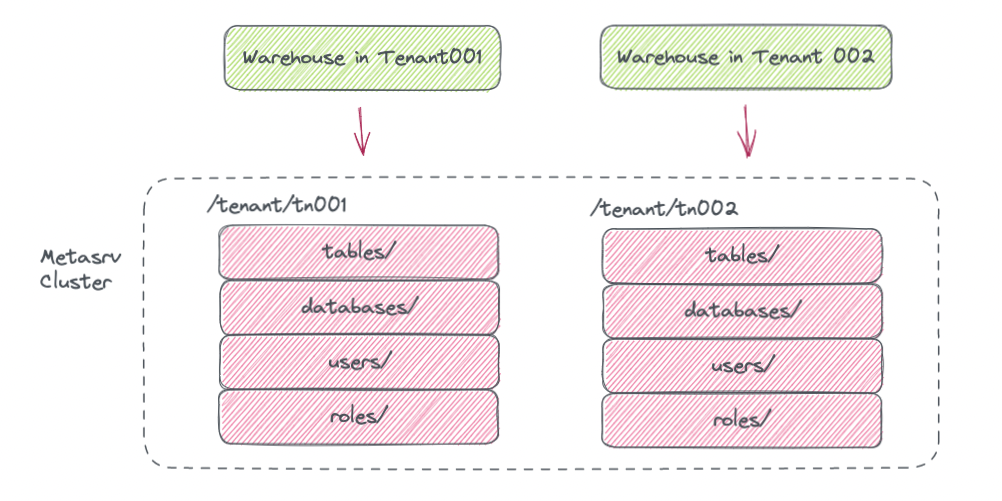
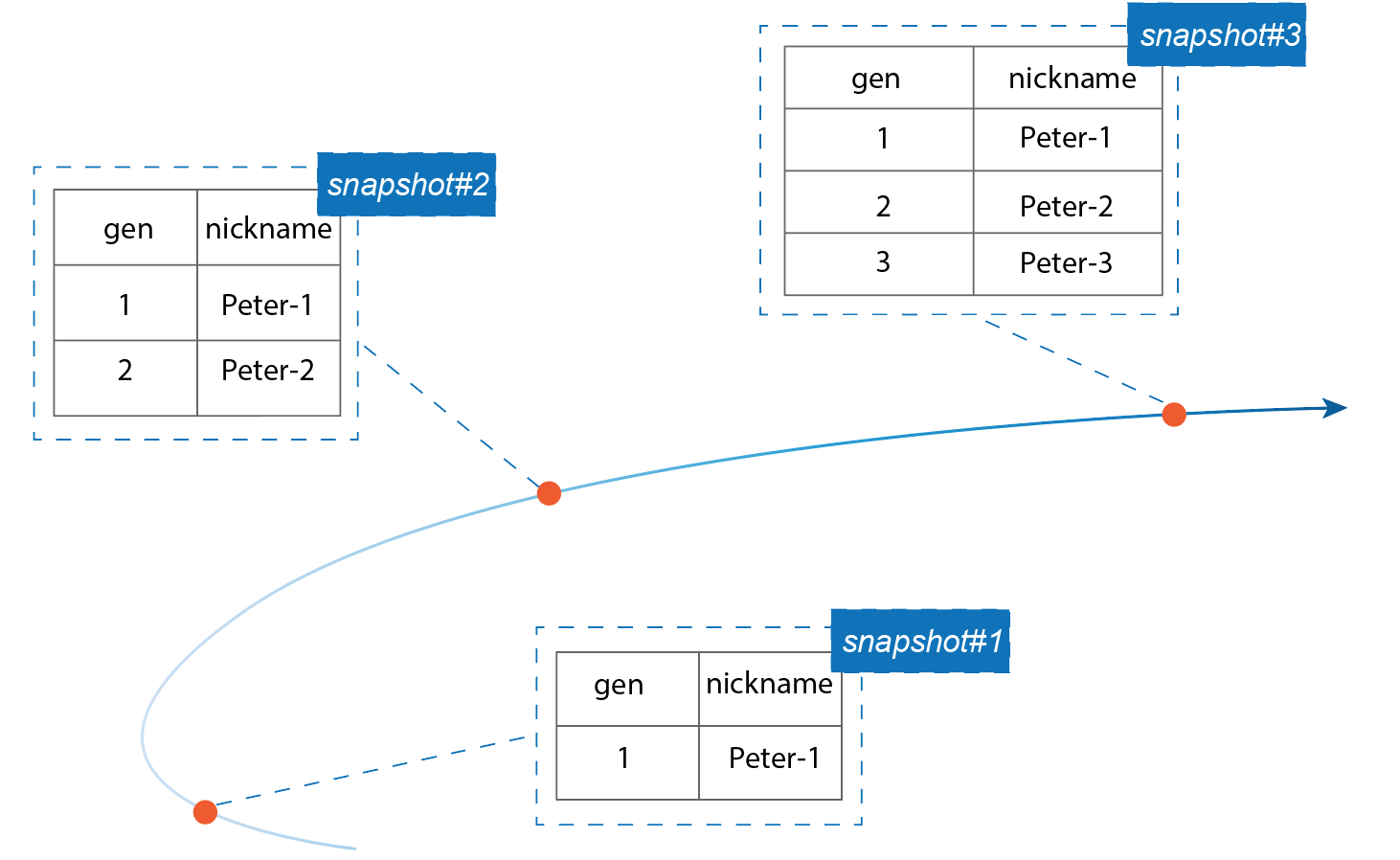
In Databend Cloud, Metasrv serves not only as a repository for storing metadata such as table structures and user authentication information, but also provides transactional support for table writes. Object storage typically does not provide strong consistency semantics for writes, so we address this limitation by using a Raft-based Metasrv cluster to ensure consistency. In Databend, each write operation on a table generates a new Snapshot file, and the write is considered successful only when the corresponding Snapshot Key is written to Metasrv, making Metasrv the foundation for implementing ACID in Databend.
As the sole stateful component in Databend Cloud's infrastructure, the reliability of Metasrv is crucial. We have implemented automated backup mechanisms and continuously conduct reliability drills on Metasrv. The openraft framework, incubated from Metasrv, is a solid foundation for ensuring correctness. It is currently the most highly acclaimed Raft framework in the Rust ecosystem and is being used in production by companies such as Microsoft and Huobi.
Data Plane
The data plane represents the path in Databend Cloud from data import, computation, to presentation. It uses the public internet's Query Gateway as the access entry point, forwarding incoming HTTPS requests from external sources to Databend instances running in Kubernetes for computation, and ultimately returning the results to the users.
Our Query protocol is based on HTTP for communication and transport layer. In a cloud-native environment, components including the Query Gateway may restart at any time due to version upgrades or machine maintenance. In such cases, compared to the 4-layer protocols like MySQL or Postgres, the stateless HTTP protocol has significant advantages. It does not require connection keep-alive, and as long as the application gracefully handles Kubernetes' exit signals, it can ensure uninterrupted user requests during version upgrades and system maintenance periods.
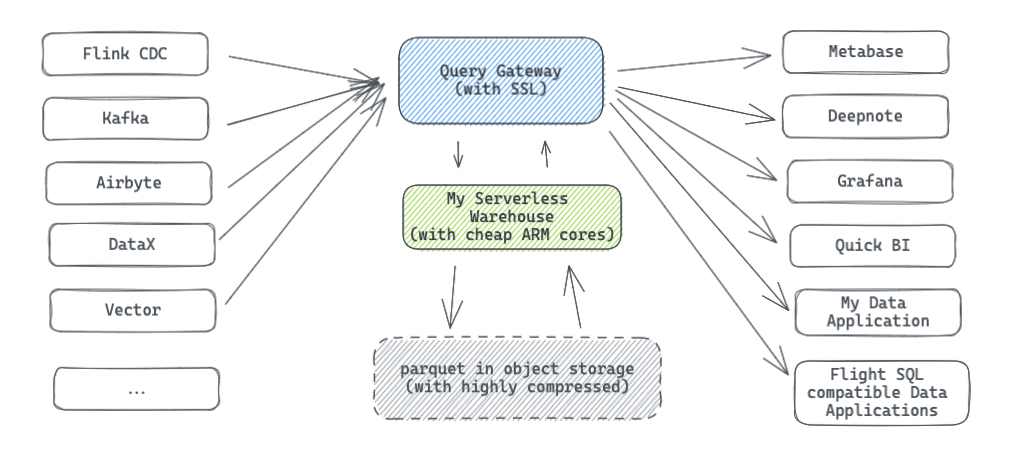
However, integrating our proprietary query protocol with the big data ecosystem has posed some challenges. We need to implement SDKs in different languages and establish one-to-one integrations with various systems, which can be a significant amount of work for a new product. Currently, we have provided SDKs in Go, Java, Python, and Rust, as well as integrations with data systems such as Metabase, Grafana, Quick BI, Deepnote, Airbyte, Kafka, DataX, and Flink CDC. We are also exploring the implementation of a protocol based on Flight SQL, leveraging the SQL protocol standards from the Arrow community, to make Databend Cloud more easily integrated with other systems and seamlessly blend into a larger ecosystem.
Auto Suspend and Auto Resume
To minimize compute resource costs, we periodically collect metrics from active warehouses. If a warehouse exceeds the suspend time, it will be put into a suspend state to release computational resources and stop incurring costs. By default, we set the auto-suspend duration for warehouses to 5 minutes, but you can adjust it to a minimum of 1 minute based on your own needs.
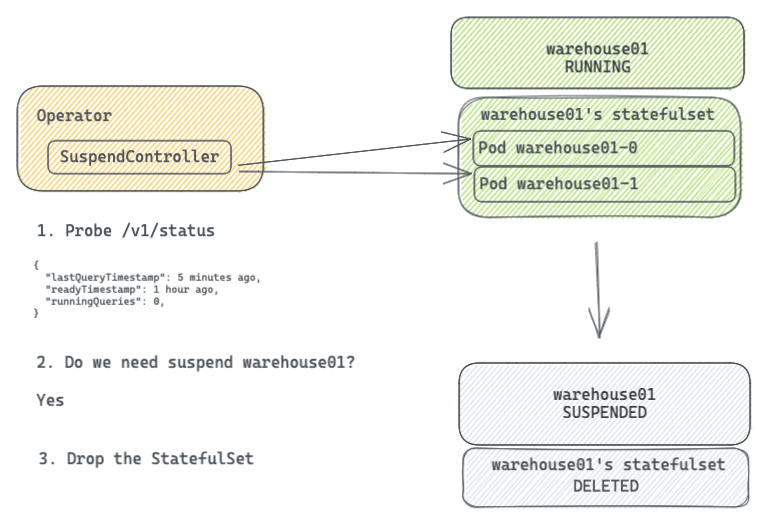
The SuspendController in the Operator continuously monitors the Pods of active warehouses by querying the /v1/status API to retrieve the running status of Databend instances. If all Pods of a warehouse do not have active queries and the time since the last activity exceeds the suspend duration, the StatefulSet of that warehouse is deleted to release compute resources.
When a request arrives at the Query Gateway for a warehouse that is not yet started, it notifies the Operator to attempt to wake up the warehouse. Once the StatefulSet is ready, the query is then forwarded for execution. Thanks to the fast startup speed of Databend instances (around 1 second), the waiting time is usually just a few seconds. With this automatic wake-up mechanism, users no longer need to worry about the status of warehouses, as each warehouse operates as a serverless service.
We did not choose serverless frameworks like Knative because we wanted to keep the control flow simple with minimal dependencies and CRD definitions to reduce maintenance costs and allow for more flexible adjustments to serverless strategies.
Multi-Cloud and Multi-Region
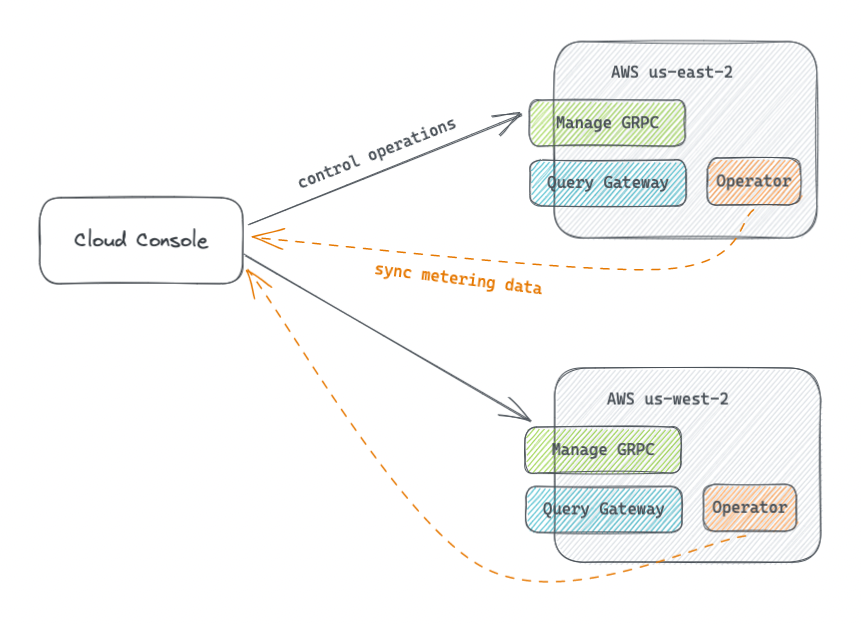
In the context of Databend Cloud architecture, as mentioned earlier, there are two main components: the data plane and the control plane. In the case of multi-cloud and multi-region deployment, the Cloud Console treats each region as a black box that exposes the entry point for the control plane.
In Databend Cloud, all supported regions are managed through Pulumi for Infrastructure as Code (IaC) management. Managing all cloud-based infrastructure resources through IaC ensures that our infrastructure environments in different regions are standardized and consistent. This allows us to create test environments that are consistent with production environments and enables us to quickly onboard new regions.
When a new region is added, the Cloud Console connects to it through Manage Grpc over the internal network. When a new user registers, the SetupTenant is called to initialize the tenant, which includes initializing an IAM Role and binding object storage prefix access permissions for the current tenant. The behavior of SetupTenant varies depending on the cloud provider, and we have adapted different initialization logic for different cloud providers.
In addition to control plane traffic, there is also additional communication for usage information synchronization. The Operators in each region asynchronously push usage and storage information of the Warehouses to the Cloud Console after collecting them. The Cloud Console centrally stores the usage information in its own database, aggregates it to generate usage statistics data, and generates monthly bills.
Data Security
Data security is the top priority of the Cloud Warehouse platform. During the development of Databend Cloud, we hope to apply the security practices of the State of Art to maximize the protection of user data security.
We hope to have strict data access isolation among tenants. At the same time, we also want to use as little as possible long-lifecycle AccessKey/SecretKey to access resources on the cloud, because once a long-lifecycle Key is leaked, it will cause huge damage. Security risks. Fortunately, most cloud vendors provide an identity authentication mechanism based on Kubernetes' Bound Service Account Token, which helps us solve this problem. It can provide a service with an automatically rotated Token (for example, automatically expires in half an hour), and establish an identity association with the IAM Role through the STS service of the cloud vendor, and then restrict the access rights of the service through IAM rules to achieve fine-grained access control.
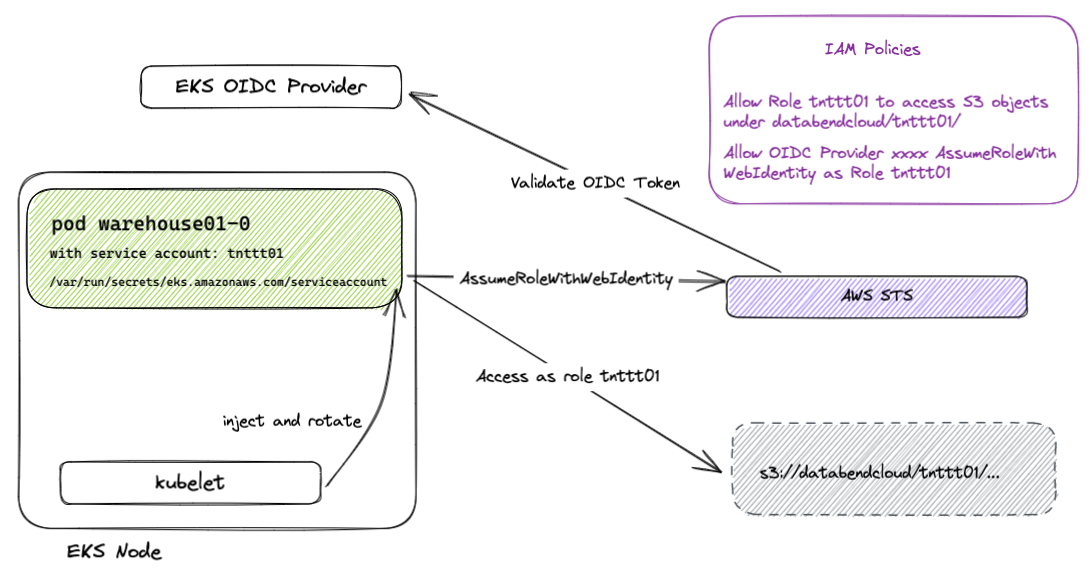
In Databend Cloud, each tenant is assigned a dedicated IAM Role during the SetupTenant process, and IAM policies are configured to restrict each tenant's access to specific prefixes within the files. This eliminates the need for long-lived access keys, making access to cloud resources such as S3 more secure and reliable.
All data stored on Databend Cloud is encrypted by default. Additionally, users can also leverage the Assume Role mechanism in Databend Cloud to mount their own S3 buckets from their AWS accounts for analysis purposes, ensuring data security while enabling data analysis capabilities.
RBAC
In Databend, users can be assigned multiple roles, and roles can have dependencies among them. However, at any given time, only one role can be active. Databend Cloud currently includes two special built-in roles: AccountAdmin and Public, which are used as administrator and regular user roles, respectively. The difference between these roles is that AccountAdmin serves as the parent role for all other roles, while Public is considered the child role of all other roles. The hierarchical relationship between these roles is approximately as follows:
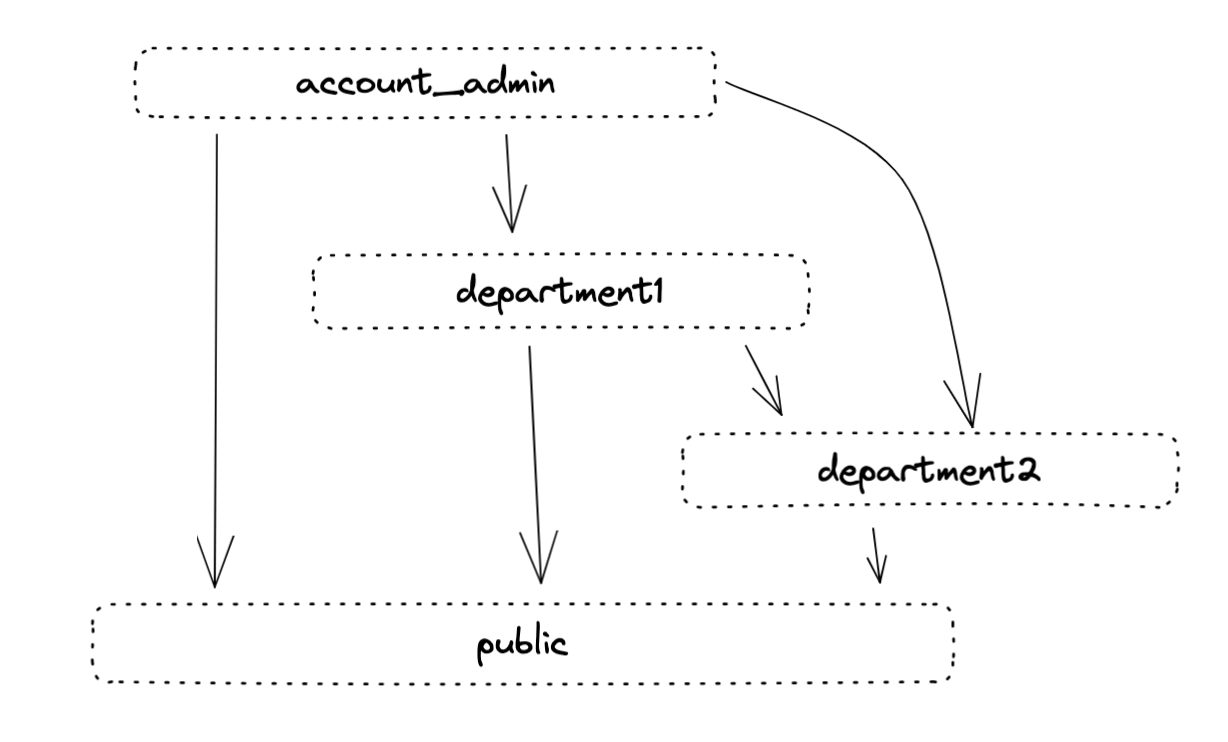
By assigning different roles and permissions to users with different responsibilities, it ensures that only authorized personnel can access sensitive data. RBAC is a significant safeguard for data security.
More Features
In addition to making Databend more user-friendly and secure as an infrastructure, we also aim to provide more possibilities through cloud services. Cloud Data Warehouse often consists of advanced features implemented as microservices. Microservices allow us to continuously iterate and enhance the capabilities of Data Cloud services, which is a key difference between cloud data warehousing and traditional data warehousing. We will continue to develop more microservices in Databend Cloud to contribute to the Data Cloud architecture. For example:
- Automatic data import pipeline: Allows automatic synchronization of data from object storage to tables in Databend Cloud, automatically detects new files and initiates imports, and users can also push new files by calling the API endpoint in real-time. Currently, only AWS is supported, with integration with other cloud providers under development.
- Automatic tiering: Allows automatically downgrading data from object storage to cheaper storage tiers, further reducing storage costs.
- Automatic compaction and optimization: Automatically initiates optimization based on metadata usage, improving query performance for free.
- Data Masking: Allows setting rules to mask specific rows and columns for specific roles, ensuring data privacy.
- Data Market: Automatically subscribes to data shared by other tenants through sharing mechanisms, creating a data market.
Summary
Now that you have gained an understanding of the design and architecture of Databend Cloud, feel free to visit https://app.databend.com to sign up and try it out! Databend Cloud is committed to providing an affordable, efficient, user-friendly, and secure Cloud Data Warehouse solution. If you have large amounts of data and are looking for a cost-effective solution to meet your analytical needs, we're here to help.