Cloud computing provides cheap, elastic, shared storage services for data-centric applications, delivering obvious benefits for modern data processing workflows: massive data volumes, high concurrency, and high throughput. As a result, more and more use cases are migrating from legacy technology stacks to data lake architectures.
However, new challenges arise when we place our data lakes in the cloud:
- Legacy data warehouses and big data analytics technologies may not be designed specifically for the cloud and object storage. There could be performance and compatibility issues that require significant effort to maintain. How can we provide a truly modern, low-cost, high-performance, high-quality analytics service for the data lake?
- Data management requirements are strengthened, with higher demands on reproducibility of analysis results and shareability of data sources. How can we make data elastic and manageable, enabling data scientists, analysts, and engineers to collaborate seamlessly under a logically consistent view?
Where there are problems, solutions arise.
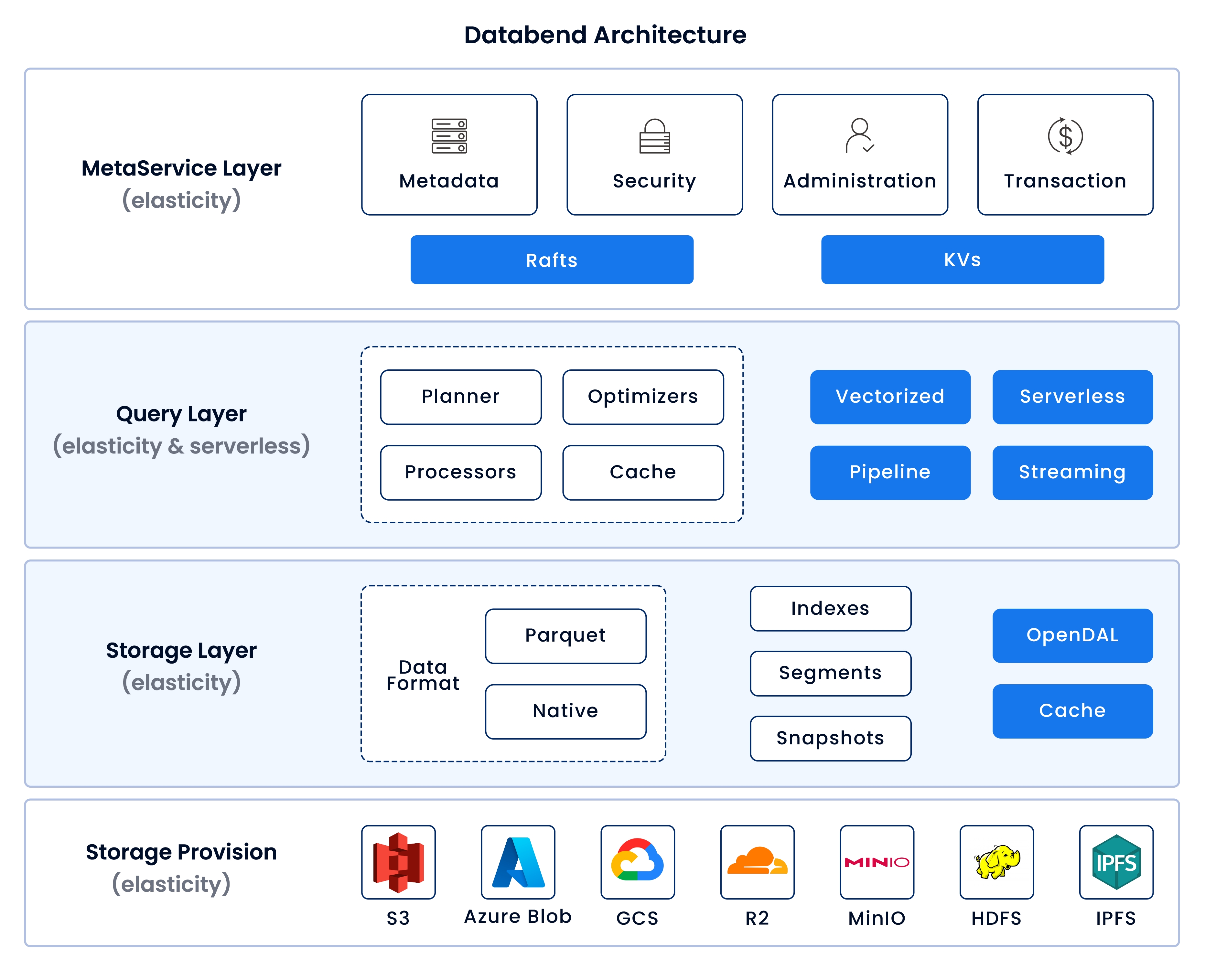
Databend builds a truly cloud-native and cross-cloud data warehouse on top of cloud object storage, designed with a serverless mindset to provide distributed, elastic, easy-to-manage high-performance query engines. It supports common structured and semi-structured data formats and integrates tightly with modern data technology stacks.
lakeFS provides solutions for shared, collaborative data processing, empowering object storage with Git-like capabilities to version control data and present logically consistent views. Meaningful branch names and commit messages can be embedded into data workflows, while unified solutions are offered for data and documents.
In this article, we combine both technologies to provide a simple, clear workshop to help you quickly build a modern data workflow.
Why You Need Databend
As data volumes explode, traditional data warehouses face huge challenges. They cannot efficiently store and process massive datasets, nor elastically scale compute and storage resources based on workloads, leading to high costs. Moreover, data processing is complex, requiring heavy investment into ETLs, while data rollback and version control are very difficult.
Databend aims to solve these pain points. It is an open-source, elastic, and workload-aware cloud data warehouse built in Rust, offering a cost-effective alternative to Snowflake. It's designed for complex analysis of the world's largest datasets.
- Cloud-Friendly: Seamlessly integrates with various cloud storages like AWS S3, Azure Blob, Google Cloud, and more.
- High Performance: Built in Rust, utilizing SIMD and vectorized processing for rapid analytics. See ClickBench.
- Cost-Efficient Elasticity: Innovative design for separate scaling of storage and computation, optimizing both costs and performance.
- Easy Data Management: Integrated data preprocessing during ingestion eliminates the need for external ETL tools.
- Data Version Control: Offers Git-like multi-version storage, enabling easy data querying, cloning, and reverting from any point in time.
- Rich Data Support: Handles diverse data formats and types, including JSON, CSV, Parquet, ARRAY, TUPLE, MAP, and JSON.
- AI-Enhanced Analytics: Offers advanced analytics capabilities with integrated AI Functions.
- Community-Driven: Benefit from a friendly, growing community that offers an easy-to-use platform for all your cloud analytics.
Why You Need lakeFS
Due to the lack of atomicity, rollback, etc in object storage, data integrity is hard to guarantee, leading to lower quality and recoverability. To protect production data, isolated copies are often required for testing, wasting resources and making collaboration difficult.
When it comes to collaboration, Git comes to mind. But Git is not designed for data management. Aside from binary data handling issues, the file size limit of Git LFS also constrains its use cases.
lakeFS provides open source data version control for data lakes – branch, commit, merge, revert – just like using Git to manage code. By supporting zero-copy isolated dev/test environments, continuous validation, atomic rollback of bad data, reproducibility, etc, you can even easily try ETL workflows on production data without worries.

Workshop: Empower Your Analytics with lakeFS
In this workshop, we will create branches in lakeFS, and analyze and transform preset data with Databend.
We highly recommend trying Databend Cloud and lakeFS cloud to skip the time-consuming environment setup and dive right into data analysis and transformation.
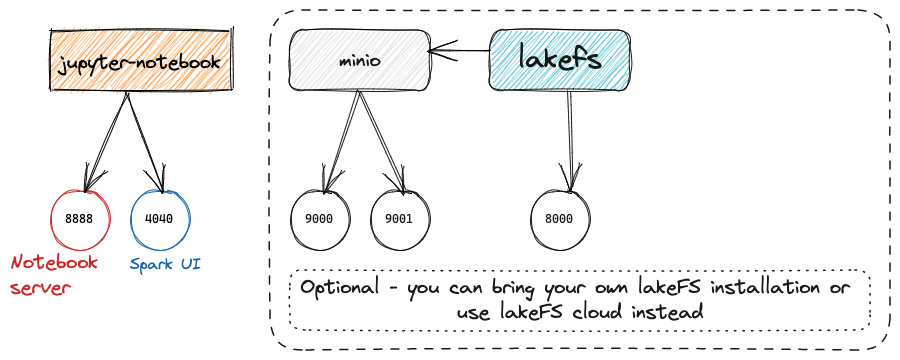
Environment Setup
The environment will include lakeFS, MinIO for object storage, Jupyter, Spark and other common data science tools, in addition to Databend. Refer to this git repo for details.
Clone the Repository
git clone https://github.com/treeverse/lakeFS-samples.git
cd lakeFS-samples
Start the Full Stack Environment
docker compose --profile local-lakefs up
Once started, you can access lakeFS and MinIO with default configurations to observe data changes in later steps.
Observe the Data
The quickstart repo is precreated in lakeFS with some preset data during environment setup. Let's do some simple observations here.
If using your own deployed lakeFS + MinIO:
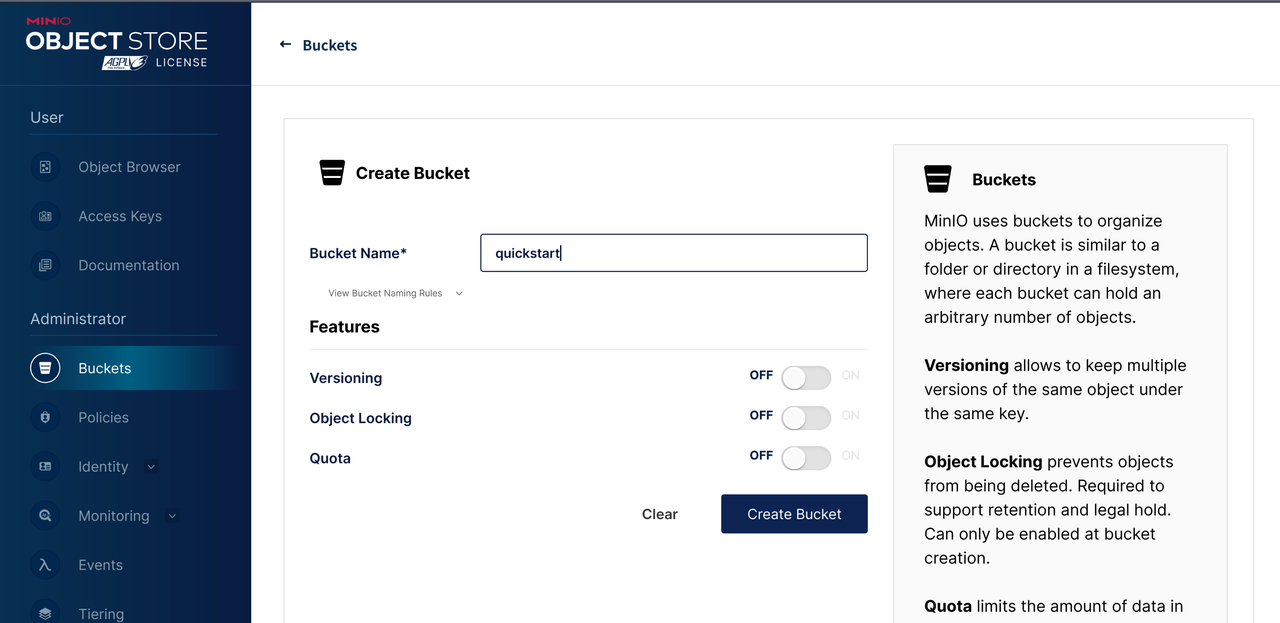
- You may need to manually create the bucket in MinIO first.
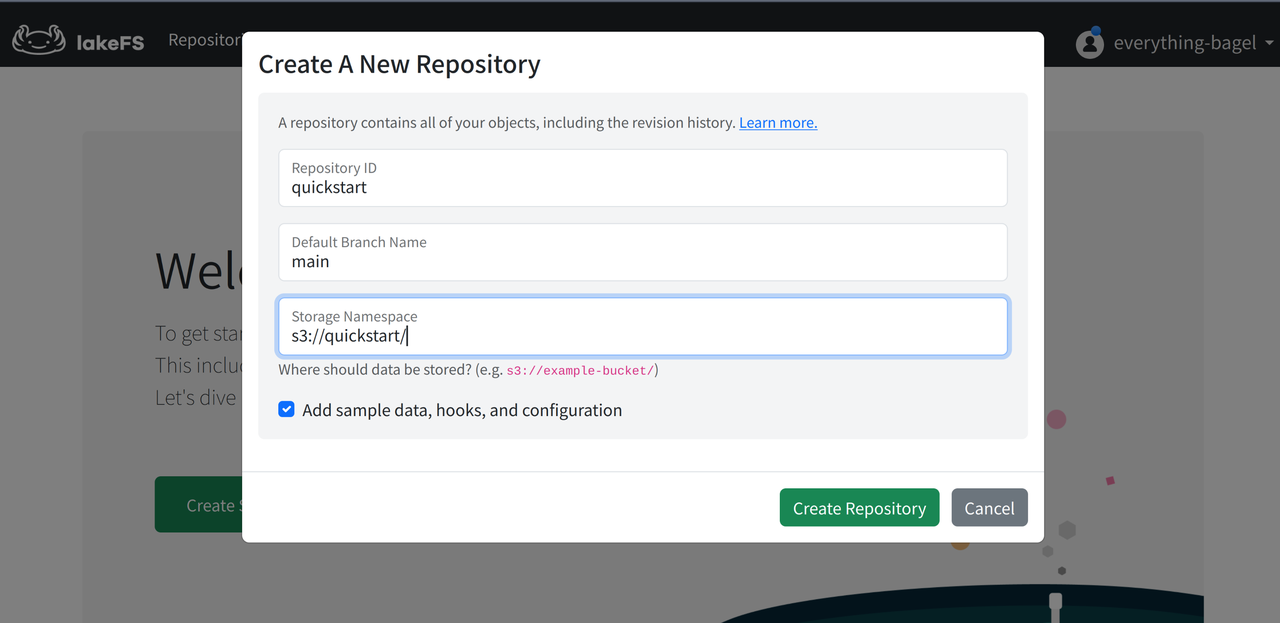
- Then create the repo in lakeFS, checking the option to populate sample data.
lakeFS
Access lakeFS at http://127.0.0.1:8000 with the Access and Secret Keys.
Open the quickstart repo. Some default data and a tutorial already exist.
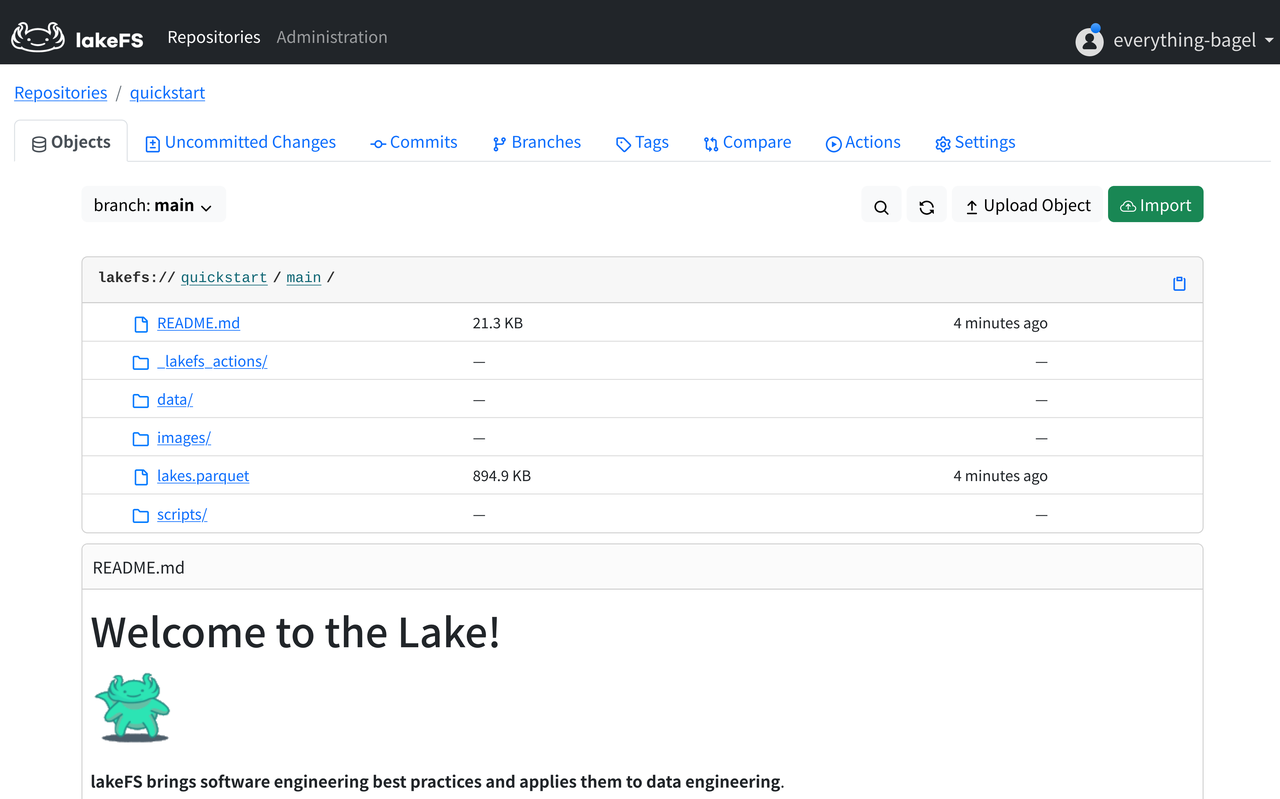
lakeFS data repos correspond closely to code repos like GitHub, with almost no learning curve. lakes.parquet contains preset data, while lakes.source.md in data/ describes data provenance. scripts/ contains validation scripts, with the full workflow under _lakefs_actions/ like GitHub Actions. README.md is the Markdown source for the following tutorial, and images/ contains all images used.
MinIO
Since we use MinIO for object storage in the experiment environment, a quickstart bucket can also be found in MinIO. This is determined by the StorageNamespace when creating the lakeFS repo.
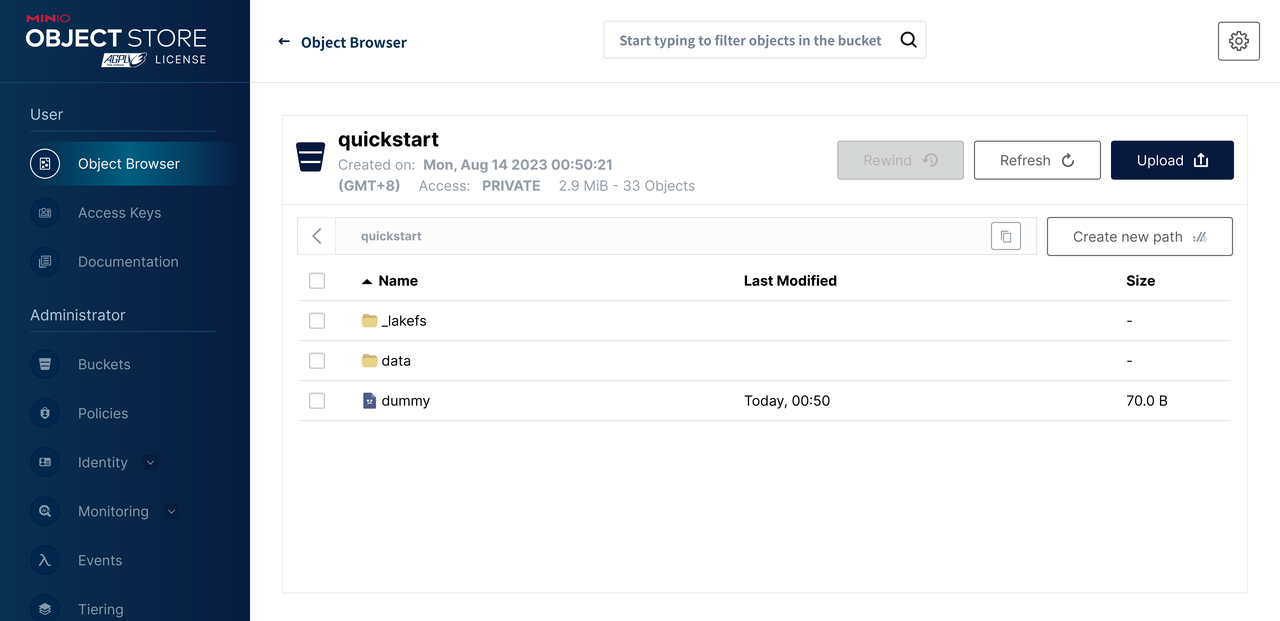
The dummy file is created when initializing the lakeFS repo to ensure we have write access to the bucket.
The _lakefs/ directory only contains two files, created during import from S3 etc, to reference original locations of imported files.
New objects written through lakeFS will be under the data/ directory.
Correspondence between Data
Open the data/ directory. It's hard to match these files to the data in lakeFS.
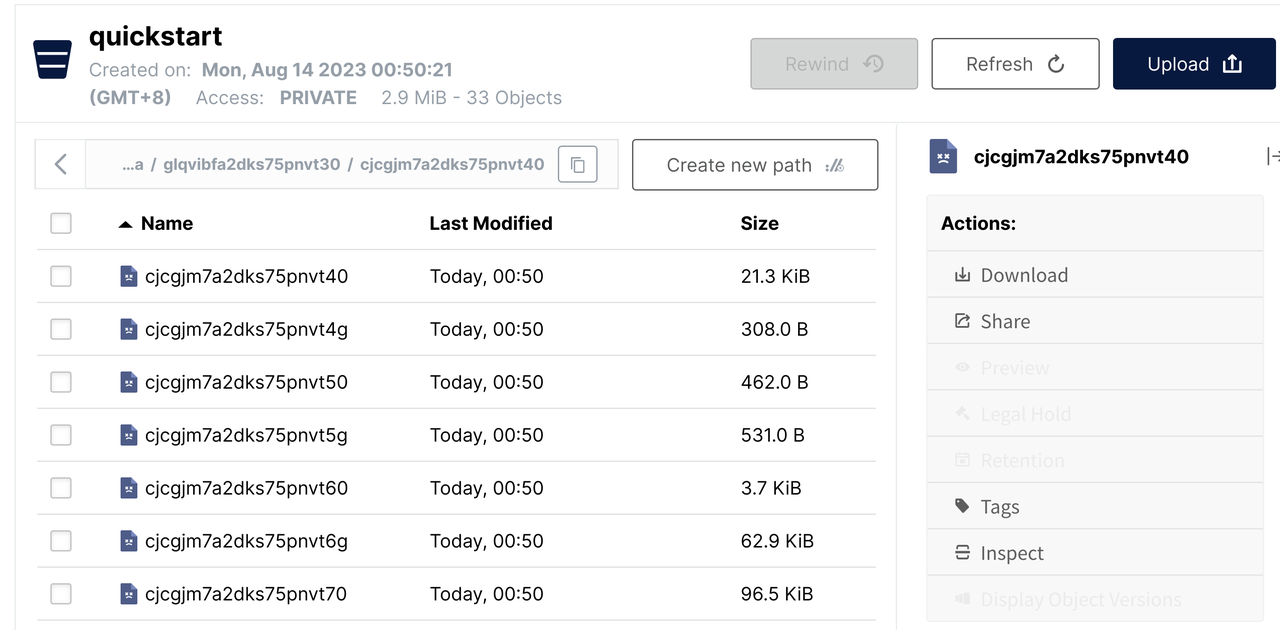
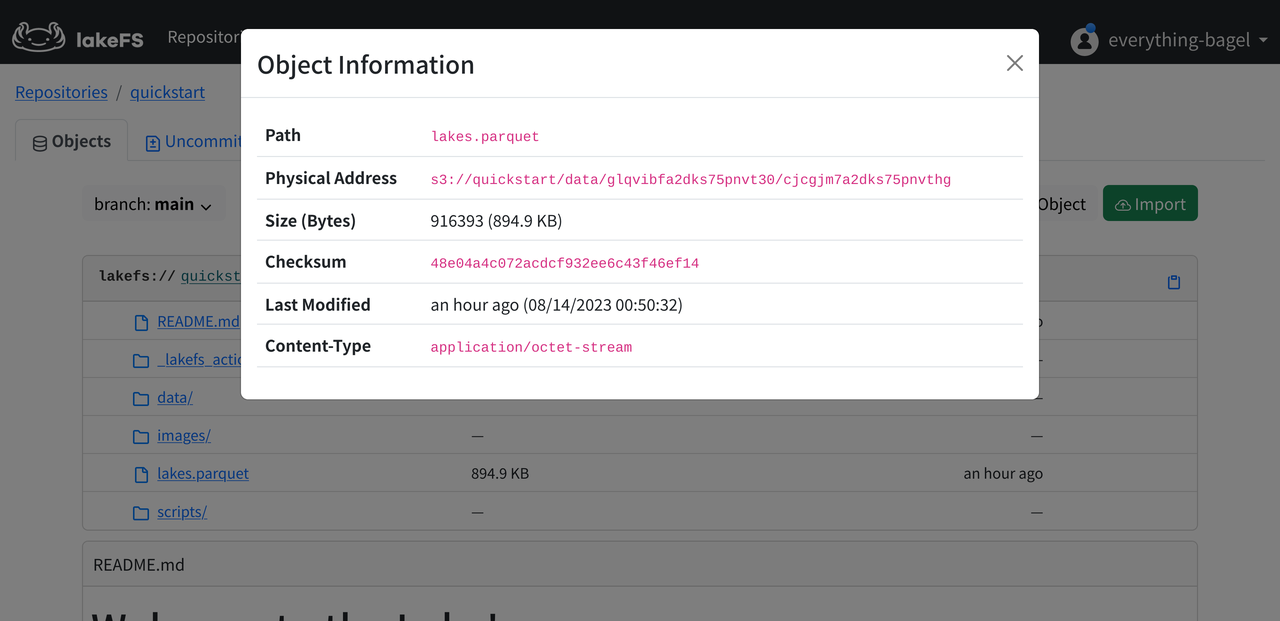
Let's switch back to lakeFS, click the gear icon beside a file, and select Object Info to easily find the mapping.
Data Analysis and Transformation
We will deploy a Databend service, mount data from lakeFS via Stage, and analyze and transform it, replacing the lakes.parquet under the denmark-lakes branch with the transformed result.
Deploy Databend
Databend's storage engine also supports Time Travel, atomic rollback, etc. No need to worry about mistakes.
We will use a single node Databend with MinIO as storage backend. Overall deployment can follow the Databend Docs, with some details below:
Since MinIO is already deployed, just open
http://127.0.0.1:9000and create adatabendbucket.Prepare log and meta data directories:
sudo mkdir /var/log/databend
sudo mkdir /var/lib/databend
sudo chown -R $USER /var/log/databend
sudo chown -R $USER /var/lib/databendEdit
databend-query.tomlto avoid port conflicts:http_handler_port = 8088Configure admin user per Docs | Configuring Admin Users. For simplicity:
[[query.users]]
name = "root"
auth_type = "no_password"Configure
[storage]to use MinIO:[storage]
type = "s3"
[storage.s3]
bucket = "databend"
endpoint_url = "http://127.0.0.1:9000"
access_key_id = "minioadmin"
secret_access_key = "minioadmin"
enable_virtual_host_style = false
Then start Databend normally:
./scripts/start.sh
We highly recommend the BendSQL client. Connect to Databend on port 8088 since http_handler_port changed.
bendsql -P 8088
Create Branch
lakeFS usage is similar to GitHub. Open the Branches page in the Web UI, and click Create Branch to make a denmark-lakes branch.
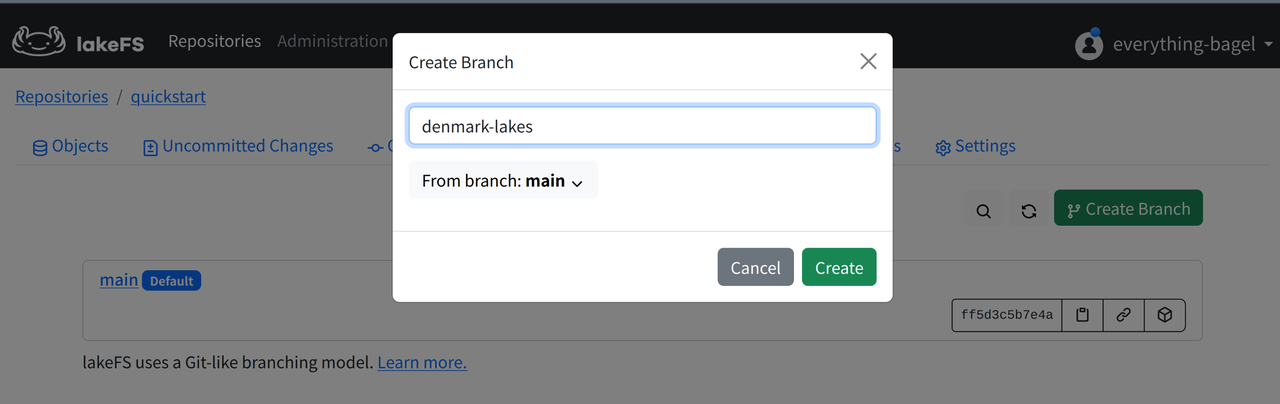
Create Stage
Databend can mount data directories in remote storage services via Stage. Since lakeFS provides S3 Gateway API, we can configure the connection as an S3 compatible service. Note the URL needs to be s3://<repo>/<branch>, and lakeFS's ENDPOINT_URL is on port 8000.
CREATE STAGE lakefs_stage
URL='s3://quickstart/denmark-lakes/'
CONNECTION = (
REGION = 'auto'
ENDPOINT_URL = 'http://127.0.0.1:8000'
ACCESS_KEY_ID = 'AKIAIOSFOLKFSSAMPLES'
SECRET_ACCESS_KEY = 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY');
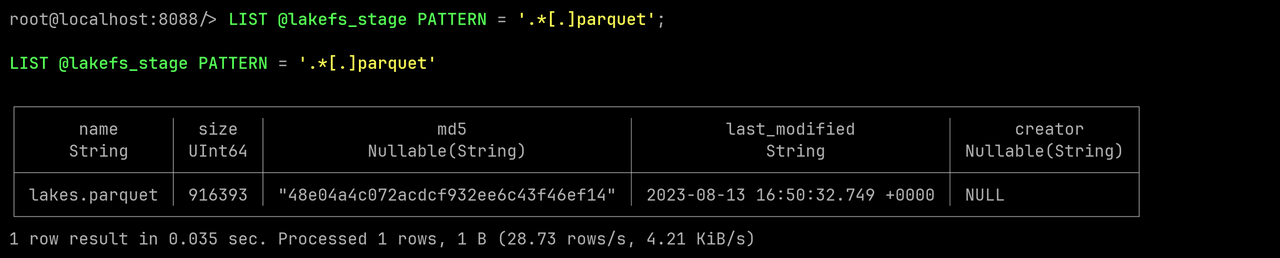
Run this SQL to filter for Parquet files in the directory:
LIST @lakefs_stage PATTERN = '.*[.]parquet';
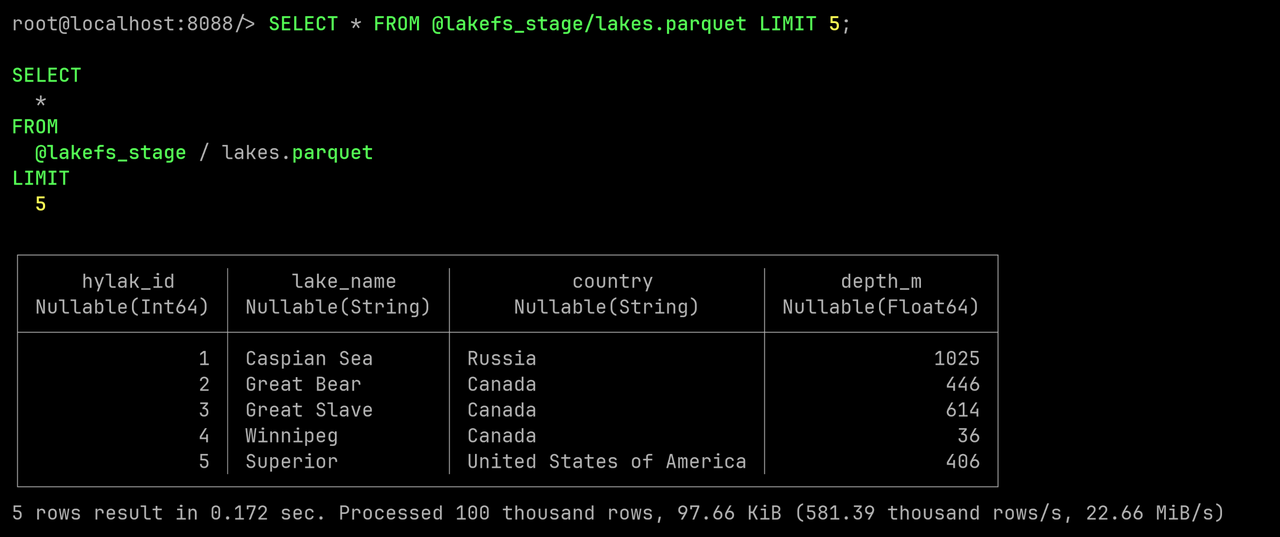
Since Databend already supports SELECT from Stage, we can query without importing:
SELECT * FROM @lakefs_stage/lakes.parquet LIMIT 5;
Create Table and Query
Let's first import the data into Databend and do some simple queries before cleaning.
Databend has built-in Infer Schema to easily create tables from files:
CREATE TABLE lakes AS SELECT * FROM @lakefs_stage/lakes.parquet;

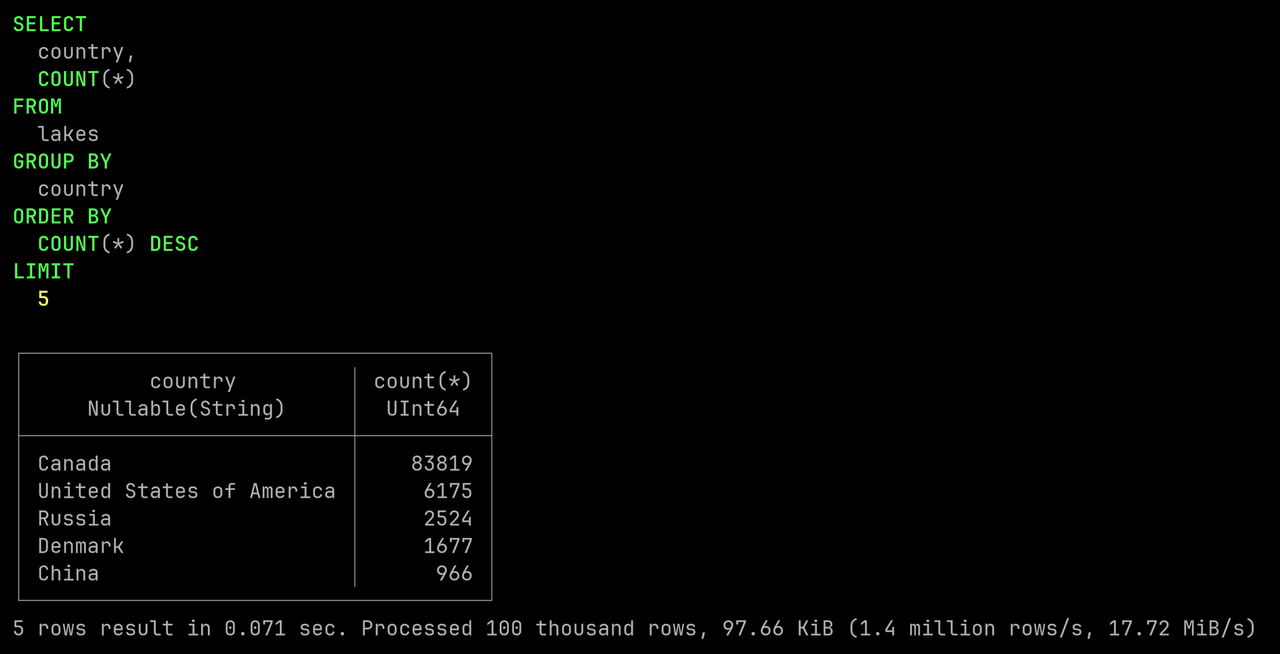
Now let's list the top 5 countries by number of lakes:
SELECT country, COUNT(*)
FROM lakes
GROUP BY country
ORDER BY COUNT(*) DESC
LIMIT 5;
Data Cleaning
Our goal here is to construct a small dataset containing only Danish lakes. This is easily achieved with a DELETE statement.
DELETE FROM lakes WHERE Country != 'Denmark';

Let's query again to check only Danish lakes remain:
SELECT country, COUNT(*)
FROM lakes
GROUP BY country
ORDER BY COUNT(*) DESC
LIMIT 5;

Write Result Back to lakeFS via PRESIGN
Here we will replace the Parquet file in the denmark-lakes branch with the cleaned data.
First export the data to the built-in anonymous Stage with COPY INTO:
COPY INTO @~ FROM lakes FILE_FORMAT = (TYPE = PARQUET);
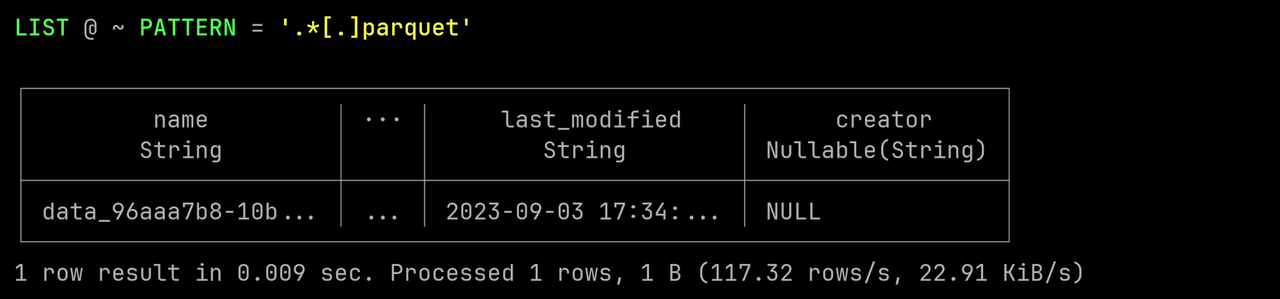
List the result files in @~:
LIST @~ PATTERN = '.*[.]parquet'
Run PRESIGN DOWNLOAD to get the download URL for the result:
PRESIGN DOWNLOAD @~/<your-result-data-file>;

In a new terminal, download via curl:
curl -O '<your-presign-download-url>'
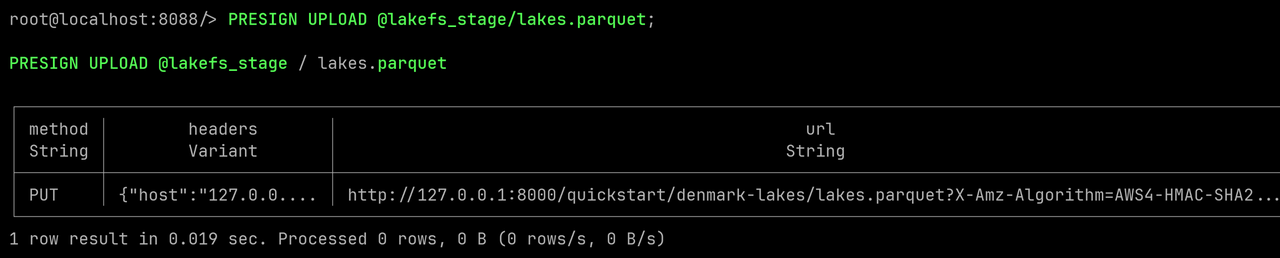
Get the upload URL with PRESIGN UPLOAD to replace @lakefs_stage/lakes.parquet:
PRESIGN UPLOAD @lakefs_stage/lakes.parquet;
Upload via curl in terminal:
curl -X PUT -T <your-result-data-file> '<your-presign-upload-url>'
The file is now replaced with the cleaned data. List the Stage again to see changes:
LIST @lakefs_stage PATTERN = '.*[.]parquet';
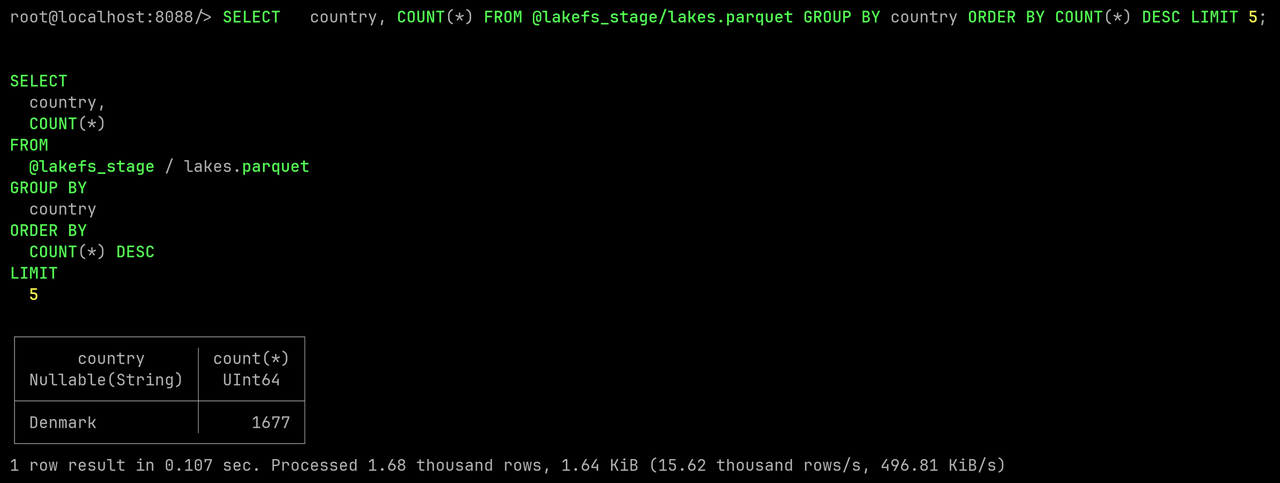
Validate by querying again:
SELECT country, COUNT(*)
FROM @lakefs_stage/lakes.parquet
GROUP BY country
ORDER BY COUNT(*) DESC
LIMIT 5;
Commit Changes
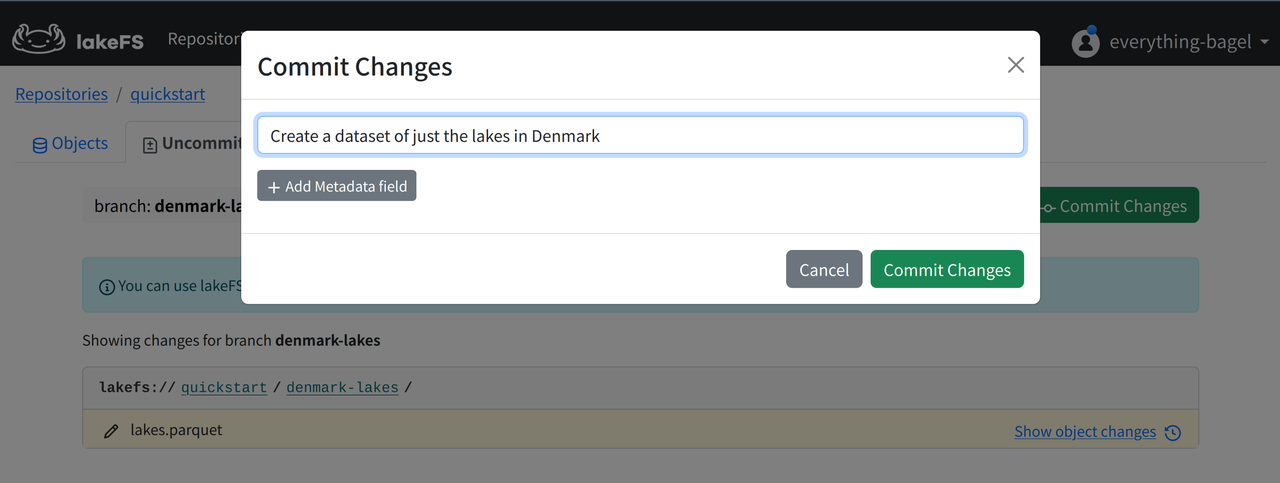
We will now commit the changes to lakeFS for persistence.
In the lakeFS Web UI, open Uncommitted Changes for the denmark-lakes branch.
Click Commit Changes, write a message, and confirm.
Verify Original Data on Main Branch
The original data on denmark-lakes is replaced with the smaller cleaned dataset. Let's switch back to main and verify the original data is intact.
Create a Stage to mount the data file again:
CREATE STAGE lakefs_stage_check
URL='s3://quickstart/main/'
CONNECTION = (
REGION = 'auto'
ENDPOINT_URL = 'http://127.0.0.1:8000'
ACCESS_KEY_ID = 'AKIAIOSFOLKFSSAMPLES'
SECRET_ACCESS_KEY = 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY');
Query the lake data and list top countries again:
SELECT country, COUNT(*)
FROM @lakefs_stage_check/lakes.parquet
GROUP BY country
ORDER BY COUNT(*) DESC
LIMIT 5;
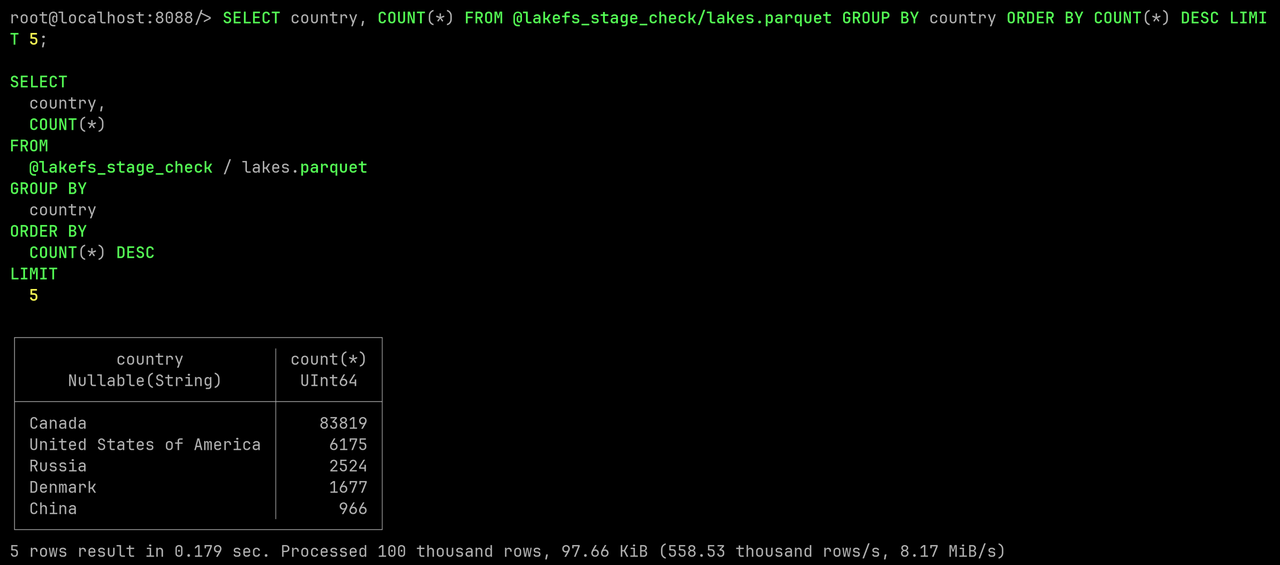
Everything on main remains unchanged. We obtained a cleaned Danish lakes dataset without affecting the original data.
Additional Challenges
In this workshop, we saw how to create isolated branches for data, perform simple queries and cleaning in Databend, and more.
For more challenges, try out branch merging and data rollback with the lakeFS tutorials, and Transforming Data on Load and Time Travel with the Databend tutorials.
We also welcome you to introduce Databend and lakeFS to production and validate with real workloads.




