
Rust for Big Data: How We Built a Cloud-Native MPP Query Executor on S3 from Scratch
 ZhiHanZSep 5, 2025
ZhiHanZSep 5, 2025

The Modern Analytics Dilemma: Throughput vs. Utilization
Database workloads are generally categorized into two types. Online Transaction Processing (OLTP) systems are optimized for managing large numbers of short, atomic transactions, such as those found in e-commerce or banking transaction applications.
In contrast, Online Analytical Processing (OLAP) systems like Snowflake and Databend are designed to execute complex queries on large volumes of historical data for business intelligence and reporting. These queries often involve large-scale aggregations and joins, demanding high computational throughput.
A fundamental challenge in designing a modern OLAP engine for the cloud is achieving high CPU utilization. While cloud object storage like Amazon S3 offers unparalleled scalability and cost-efficiency, it introduces a significant performance bottleneck: network latency for data access is thousands of times higher than for local disks.
For a query engine, this creates a dilemma: how do you keep expensive CPU cores busy when the data they need is slow to arrive? This is the central conflict between maximizing computational throughput and achieving efficient resource utilization. The following sections explore why traditional query engine architectures fail to solve this problem and how a new approach is required.
The Problem with Tightly-Coupled Architectures
Traditional data warehouses were built on a "shared-nothing" architecture where each server in a cluster has its own dedicated CPU, memory, and local disk. In this model, compute and storage are tightly coupled. While this design was effective for on-premise disk based hardware, it creates significant operational friction in the elastic environment of the cloud.
- Scaling requires massive data shuffling. To add more compute power, you must add more servers. This triggers a rebalancing process where terabytes of data are redistributed across the cluster. This operation can take hours or even days, during which query performance is severely degraded.
- Failures are catastrophic. If a node goes down, its share of the data becomes unavailable. The system must initiate a complex and time-consuming recovery process, rebuilding the lost state from replicas on other nodes. For an on-call engineer, this means a stressful, all-night incident.
- Resources are wasted. Clusters are often provisioned for peak load, such as end-of-quarter reporting. For the rest of the time, this expensive capacity sits idle, yet you continue to pay for it 24/7.
The Cloud-Native Answer: Separating Compute and Storage and Stateless Computing
The solution to these problems is to decouple compute from storage. In this modern, stateless architecture, data lives in a central, durable object store like Amazon S3. Compute nodes become ephemeral, interchangeable resources that can be spun up to run queries and spun down when idle. This design offers transformative benefits:
- Instant Elasticity: Scale your compute cluster from one to a thousand nodes in seconds, without moving any data.
- Zero-Downtime Resilience: If a compute node fails, it is simply replaced. There is no data to recover, so the system continues operating without interruption.
- Pay-for-Use Efficiency: Match compute resources precisely to your workload, eliminating idle capacity and reducing costs.
This architecture is made possible by the unique properties of cloud object storage. Let's look at why S3 is the ideal foundation.
Why S3 is the Foundation for Modern Analytics
To build a high-performance query engine on a stateless architecture, the storage layer must provide the right mix of cost, durability, and, most importantly, consistency. S3 meets these needs perfectly.
The Economic Case for S3
Object storage is dramatically more cost-effective than the block storage (like EBS) used in traditional architectures. For example, storing 100TB of data on S3 Standard costs approximately $2,300 per month, compared to around $8,000 per month for EBS gp3 volumes—a nearly 3.5x saving on storage alone. While S3 also charges for data access requests, these costs are negligible compared to the operational overhead and wasted capacity of stateful clusters.
S3's Strong Consistency Guarantee
A critical enabler for building reliable systems on S3 was its 2020 update to provide strong read-after-write consistency. This means that once an object is written or updated, any subsequent read request is guaranteed to see the latest version. This eliminated the need for complex and error-prone workarounds to handle eventual consistency, making S3 a viable storage layer for not just data, but also critical metadata and transaction coordination.
The New Rules: Engineering for Cloud Object Storage
While S3 provides a powerful foundation, its characteristics are fundamentally different from a local filesystem. Building a high-performance query engine requires embracing a new set of design constraints.
Rule #1: High Latency is the Norm
The most significant challenge is latency. A read from a local NVMe SSD takes microseconds, while a GET request to S3 in the same region takes tens or even hundreds of milliseconds—a 1,000x to 5,000x difference. A traditional query engine that blocks a thread while waiting for data would spend over 99% of its time idle. To achieve high performance, the engine must be designed to do useful work while I/O is in flight, a concept known as asynchronous processing.
Rule #2: Every Operation Has a Cost
Unlike local disk I/O, every S3 API call has a price. For example,
LIST
GET
Rule #3: The API is Not a Filesystem
S3 is an object store, not a POSIX-compliant filesystem. It lacks fundamental operations like atomic
rename
append
Rule #4: System Components Run at Different Speeds
In a cloud-native system, different components operate at vastly different speeds. S3 might deliver data at 3 blocks per second, while the CPU can process 8 blocks per second, and the client can only consume 2 blocks per second. Without a mechanism to manage this flow, the system will either crash from memory overload or starve from a lack of data. This requires a sophisticated backpressure system that allows components to signal when they are overwhelmed or idle.
Part 2: Why Cloud Storage Breaks Traditional Query Engines
To understand why a new query executor is necessary, we first need to look at the two dominant models in traditional database systems and see how their core assumptions are violated by the realities of cloud object storage.
A Quick Tour of Classic Engine Designs
The Pull-Based "Volcano" Model
The Volcano model, also known as the iterator model, has been a staple of database design since the 1990s. It works like a demand-driven supply chain. An operator at the top of the query plan (e.g., the final
SORT
JOIN
next()
SCAN
// The core interface for the Volcano model
trait Iterator {
// Each call to next() pulls one unit of data from a child operator.
fn next(&mut self) -> Option<Tuple>;
}
 This model is elegant and simple. It also provides a form of natural backpressure: an operator can't be overwhelmed with data because it only gets data when it explicitly asks for it.
This model is elegant and simple. It also provides a form of natural backpressure: an operator can't be overwhelmed with data because it only gets data when it explicitly asks for it.
The Push-Based "Vectorized" Model
Later, systems like MonetDB/X100 popularized vectorized execution, a push-based model that works more like an assembly line. Instead of pulling data one tuple at a time, operators process data in large batches (or "vectors") of thousands of rows. When an operator finishes with a batch, it pushes the result to the next operator in the pipeline.
// In a push model, operators process entire batches at once.
trait PushOperator {
fn process(&mut self, batch: DataBatch);
}
struct DataBatch {
columns: Vec<ColumnVector>,
row_count: usize, // Typically 1024-8192 rows
}
 This approach is highly efficient for CPU-intensive tasks because it amortizes the cost of function calls over many rows and opens up opportunities for SIMD (Single Instruction, Multiple Data) optimizations.
This approach is highly efficient for CPU-intensive tasks because it amortizes the cost of function calls over many rows and opens up opportunities for SIMD (Single Instruction, Multiple Data) optimizations.
Where the Old Models Fail in the Cloud
Both models work well when data is on a fast, local disk. However, their performance collapses when faced with the high latency and unpredictability of cloud object storage.
The Latency Trap: How the Pull Model Wastes CPU Cycles
The Volcano model's greatest weakness in the cloud is its synchronous, blocking nature. When the
SCAN
next()
// In a pull model, the entire thread blocks waiting for S3.
impl Iterator for S3Scan {
fn next(&mut self) -> Option<DataBlock> {
// This call blocks for 50-100ms, stalling the CPU.
let block = block_on(s3.get_object(key))?;
decode(block)
}
}
As Databend's engineers discovered, "S3 can read three blocks per second... our CPU can actually process eight blocks per second." The pull model simply cannot keep the CPU fed with data, causing utilization to plummet.
The Memory Bomb: How the Push Model Causes Overflows
The push model, on the other hand, runs into a different problem: memory exhaustion. S3 throughput can be bursty and unpredictable. A sudden flood of data from S3 can quickly overwhelm a downstream operator (like a
JOIN
AGGREGATE
SCAN
// Without backpressure, fast S3 reads can flood downstream operators.
async fn scan_s3(output_channel: Sender<DataBlock>) {
for key in keys {
let block = s3.get_object(key).await?; // Throughput is unpredictable.
// If the output_channel is full, this will either block or error.
output_channel.send(block)?;
}
}
Redefining the Requirements for a Cloud-Native Executor
The failures of these traditional models reveal a new set of requirements for any query engine designed to run efficiently on cloud object storage:
- Embrace Asynchrony: The engine must never block a thread waiting for I/O. It should be able to issue an S3 request and then switch to other useful work, such as processing data that has already arrived. This is the only way to hide latency and keep the CPU busy.
- Implement Explicit Backpressure: The engine needs a built-in flow control mechanism that allows slower operators to signal to faster upstream operators to "slow down." This prevents memory overruns and ensures system stability.
- Manage Resources Carefully: The engine must be aware of its resource consumption, particularly memory. It should bound the amount of data it prefetches from S3 to avoid OOM errors while still keeping enough data on hand to hide latency.
- Be Cost-Aware: The engine should understand the S3 cost model and actively work to minimize expensive API calls, for example by batching small reads into larger ones or avoiding unnecessary operations.LIST
Fulfilling these requirements is not possible by simply patching the old models. It demands a new architecture, built from the ground up for the cloud. This leads to the emergence of a hybrid, event-driven actor model, which combines the best aspects of both pull and push systems in an asynchronous framework.
Part 3: A New Foundation: Building an Asynchronous Executor
To overcome the limitations of traditional models, we need a new foundation built on asynchronous execution. This section explains the core concepts that make Databend's actor-based executor possible.
The Core Problem, Visualized
Let's revisit the chess analogy. A traditional, synchronous query engine is like a grandmaster who plays one full game to completion before starting the next. An asynchronous engine is a grandmaster who walks the room, making one move at each table. Let's map the concepts:
- The Grandmaster is the CPU thread.
- Each Opponent is a data source, like an S3 object.
- Making a Move is issuing an I/O request (e.g., ).s3.get_object
- The Opponent's Thinking Time is the I/O latency (50-200ms).
In the synchronous model, the grandmaster (CPU) spends most of their time just waiting for one opponent to think. In the asynchronous model, the grandmaster uses that waiting time to service other opponents, keeping busy and productive.
The Numbers That Define the Game
The scale of this waiting time is staggering. Let's put it in perspective:
| Operation | Latency | What a CPU Could Do in That Time |
|---|---|---|
| CPU Instruction | 0.3 ns | 1 instruction |
| L1 Cache Hit | 1 ns | ~3 instructions |
| RAM Access | 100 ns | ~300 instructions |
| SSD Read (4KB) | 100 µs | ~300,000 instructions |
| S3 GET Request | 50-200 ms | 150-600 MILLION instructions |
During the time it takes to complete a single S3 request, a CPU core could have executed hundreds of millions of instructions. A synchronous query engine forces the CPU to waste this potential. An asynchronous engine is designed specifically to reclaim it.
How Rust's async/await Enables Concurrency
Rust provides a powerful, zero-cost abstraction for building asynchronous systems:
async
await
-
A Thread is like a dedicated worker. The operating system gives it a task, and it works on it exclusively. If it needs to wait for something (like a file to download), it stops completely, consuming system resources while idle. Managing many threads is expensive.
-
An Async Task is like a single, highly-efficient worker juggling multiple assignments. When one assignment is blocked (e.g., waiting for a network response), the worker immediately switches to another that's ready to make progress. This is managed by an async runtime (like Tokio), not the OS, making it extremely lightweight.
// THREAD-BASED: The entire OS thread is frozen, wasting resources.
fn fetch_data_sync() -> String {
let response = http::get("api.example.com"); // BLOCKS for 100ms
response.text() // The thread does nothing during the wait.
}
// ASYNC TASK: The thread is free to do other work.
async fn fetch_data_async() -> String {
// `.await` signals a potential waiting point. If this call has to wait,
// the function pauses and yields control back to the runtime.
let response = http::get("api.example.com").await;
response.text().await
}
The Magic Behind async
: Futures and State Machines
async
Here's the key insight: calling an
async
Future
A
Future
async
.await
// What you write:
async fn fetch_two_objects() {
let obj1 = s3.get("key1").await;
let obj2 = s3.get("key2").await;
}
// What Rust conceptually generates:
enum FetchState {
Start,
WaitingForFirst { s3_future: S3GetFuture },
WaitingForSecond { obj1: Object, s3_future: S3GetFuture },
Done,
}
The async runtime's job is to repeatedly
poll
Future
Poll::Ready
Poll::Pending
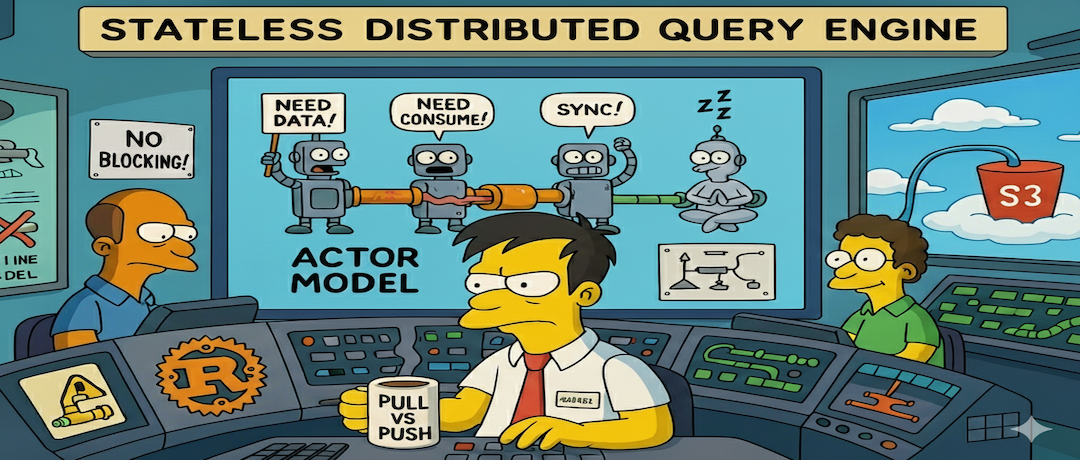
This isn't just a theoretical concept. Databend's executor is built around a similar state-based
Event
// From /src/query/pipeline/core/src/processors/processor.rs
#[derive(Debug)]
pub enum Event {
NeedData, // PULL: "I'm idle and need input to work on."
NeedConsume, // BACKPRESSURE: "My output buffer is full, please wait."
Sync, // PUSH: "I have data and can do CPU-bound work right now."
Async, // PUSH: "I'm starting a long I/O task. Don't wait for me."
Finished, // DONE: "I have no more work to do."
}
The executor uses these events to intelligently schedule tasks, ensuring no thread is ever blocked waiting for S3.
The Payoff: True Concurrency
This model's real power shines when you launch multiple operations at once. Because
async
// SEQUENTIAL: Total time = 100ms + 100ms = 200ms
async fn fetch_sequential() {
// .await pauses the function, so the second request doesn't start
// until the first one is completely finished.
let obj1 = s3.get("key1").await;
let obj2 = s3.get("key2").await;
}
// CONCURRENT: Total time = max(100ms, 100ms) = 100ms
async fn fetch_concurrent() {
// Calling the async functions returns two futures immediately.
// The underlying I/O requests are initiated at the same time.
let fut1 = s3.get("key1");
let fut2 = s3.get("key2");
// `join!` waits for both futures to complete. The total wait time
// is only as long as the single longest request.
let (obj1, obj2) = futures::join!(fut1, fut2);
}
For a query reading hundreds of S3 files, this is a game-changer. It allows the engine to saturate the network connection, hiding the latency of individual requests and maximizing throughput.
Separating Work: The I/O and CPU Pools
An async runtime is highly optimized for I/O-bound tasks—short bursts of work interspersed with long waits. It is not designed for long-running, CPU-intensive computations (like decompressing data or running vectorized SIMD computation or complex filters).
A CPU-intensive task running on an async worker thread would monopolize it, preventing the runtime from polling other futures. This starves the entire system of I/O and defeats the purpose of async execution.
Databend solves this by using two separate thread pools, managed by the Tokio runtime:
- I/O Pool: A multi-threaded runtime with a small number of threads dedicated to managing thousands of I/O-bound async tasks.
- CPU Pool: A separate pool of threads, typically matching the number of CPU cores, for heavy computation.
This separation is critical. It ensures that expensive computations don't stall the I/O event loop, allowing the query engine to remain responsive and keep the data flowing smoothly through the pipeline.
// I/O-optimized pool for managing network events.
let io_runtime = tokio::runtime::Builder::new_multi_thread()
.worker_threads(16) // A modest number of threads can handle vast I/O.
.enable_io()
.build();
// CPU pool - for computation
let cpu_pool = tokio::runtime::Builder::new_multi_thread()
.worker_threads(num_cpus::get())
.build();
// Use appropriately:
async fn process_s3_data(key: String) {
// 1. I/O-bound work runs on the I/O pool
let compressed_data = s3_client.get_object(&key).await?;
// 2. CPU-bound work is explicitly moved to the CPU pool
let decompressed_data = tokio::task::spawn_blocking(move || {
decompress_zstd(&compressed_data) // Heavy computation
}).await?;
// ... further processing
}
Part 4: Inside Databend's Executor: A Deep Dive into the Actor Model
The previous sections established why a new architecture is needed. Now, let's dive into how Databend's executor is built. It's a hybrid, event-driven actor model that combines the best of pull and push systems. We'll explore its four core components: Processors, Ports, the Scheduler, and the Backpressure mechanism.
1. The Processor: An Independent Actor
In our model, every query operator (like a
Filter
Join
S3Scan
Processor
Processor
The core of this design is the
Processor
// From /src/query/pipeline/core/src/processors/processor.rs
#[async_trait::async_trait]
pub trait Processor: Send {
fn name(&self) -> String;
// The heart of the actor: reports its current state to the scheduler.
fn event(&mut self) -> Result<Event>;
// Performs synchronous, CPU-bound work.
fn process(&mut self) -> Result<()>;
// Performs asynchronous, I/O-bound work.
async fn async_process(&mut self) -> Result<()>;
}
Each processor is a self-contained state machine. The
event()
2. The Event System: The Actor's Mailbox
Processors communicate their state via an
Event
// From /src/query/pipeline/core/src/processors/processor.rs
#[derive(Debug)]
pub enum Event {
// PULL Signal: "I'm idle and need input from my parent."
NeedData,
// BACKPRESSURE Signal: "My output buffer is full. Tell my parent to stop sending data."
NeedConsume,
// PUSH Signal (CPU): "I have data and am ready for synchronous, CPU-bound work."
Sync,
// PUSH Signal (I/O): "I'm starting a long-running async I/O task. Don't wait for me."
Async,
// "I have no more work to do and will not produce more data."
Finished,
}
This event-driven approach is what makes the system a "hybrid" of pull and push. A processor can
NeedData
Sync
3. Ports: Lock-Free Communication Channels between Query Operators
If processors are actors, Ports are their mailboxes. They are the channels through which data blocks flow from one processor to another. A key innovation in Databend is that these ports are designed for lock-free communication using atomic operations, which is critical for high-performance multi-threading.
An
OutputPort
InputPort
// From /src/query/pipeline/core/src/processors/port.rs
pub struct InputPort { /* ... internals ... */ }
impl InputPort {
// Checks if the port has data ready to be processed.
pub fn has_data(&self) -> bool;
// Pulls the data block from the port.
pub fn pull_data(&self) -> Option<Result<DataBlock>>;
}
pub struct OutputPort { /* ... internals ... */ }
impl OutputPort {
// Pushes a data block to the connected input port.
pub fn push_data(&self, data: Result<DataBlock>);
// Checks if the downstream processor is ready to accept more data.
// This is the core of our backpressure mechanism.
pub fn can_push(&self) -> bool;
}
Instead of using slow mutexes or locks, ports use atomic flags (like
HAS_DATA
NEED_DATA
OutputPort
push_data
InputPort
has_data
4. The Scheduler: The Orchestra Conductor
The scheduler is the central loop that orchestrates all the processor actors. It continuously polls processors for their latest
event()
Here is a simplified view of the scheduler's logic:
// Conceptual logic from /src/query/service/src/pipelines/executor/executor_graph.rs
// The scheduler maintains queues of processors ready for work.
let mut sync_queue: Vec<Processor>;
let mut async_queue: Vec<Processor>;
// Main scheduling loop
loop {
for processor in all_processors {
match processor.event() {
// This processor is ready for CPU work. Add it to the sync queue.
Event::Sync => sync_queue.push(processor),
// This processor needs to do I/O. Add it to the async queue.
Event::Async => async_queue.push(processor),
// This processor is waiting for data or for its output to be consumed.
// Do nothing; it will be polled again later.
Event::NeedData | Event::NeedConsume => { /* skip */ },
// This processor is done. Remove it from the pipeline.
Event::Finished => finish_processor(processor),
}
}
// Execute all ready tasks.
execute_sync_tasks(sync_queue);
execute_async_tasks(async_queue);
}
When a processor returns
Event::Async
async_process
Event::Sync
5. Backpressure: The System's Self-Regulating Valve
The final piece of the puzzle is backpressure. What happens when a fast S3 reader is feeding data to a slow
JOIN
JOIN
Our architecture solves this elegantly. The backpressure mechanism is built directly into the
event()
// A typical processor's event logic for handling backpressure.
impl Processor for FilterProcessor {
fn event(&mut self) -> Result<Event> {
// 1. Check downstream first. Is the next operator ready for data?
if !self.output_port.can_push() {
// If not, we can't produce more data. Signal that we're waiting for the consumer.
return Ok(Event::NeedConsume);
}
// 2. If downstream is ready, check upstream. Do we have data to process?
if !self.input_port.has_data() {
// If not, signal that we need data from our parent.
return Ok(Event::NeedData);
}
// 3. If downstream is ready AND we have data, we are ready for CPU work.
Ok(Event::Sync)
}
}
This simple, local check propagates backpressure through the entire query pipeline automatically.
- A slow operator causes its input port to fill up.FinalAgg
- The upstream operator callsPartialAggand it returnsoutput_port.can_push().false
- The returnsPartialAgg. The scheduler sees this and idles the processor.Event::NeedConsume
- This effect cascades all the way back to the , which eventually stops fetching new data from S3 because its downstream consumer is busy.S3Reader
- Memory usage stabilizes. Once the slow operator catches up, its input port drains, returnscan_push(), and the whole pipeline seamlessly resumes.true
Multi-threaded Execution: Scaling Out with Pipeline Parallelism
When executing queries on multiple threads, Databend duplicates the pipeline rather than splitting individual operators. This approach maintains the simplicity of the actor model while achieving parallelism.
A Tale of Two Queries: From One Thread to Many
Let's see how this works with a simple aggregation query.
Scenario 1: A Single Worker (
MAX_THREADS = 1
SET MAX_THREADS = 1;
SELECT SUM(number) FROM numbers(10);
The execution plan is a straight line, a single assembly line from source to sink(tips using
EXPLAIN PIPELINE

With two threads:
SET MAX_THREADS = 2;
SELECT SUM(number) FROM numbers(10);
The graph becomes:

The key observation: source and partial aggregation operators are duplicated, while the final aggregation remains single-threaded after a
Resize
Keeping Workers Fed: A Smart Task System with Work-Stealing
With many threads working in parallel, how do we distribute tasks efficiently and ensure no worker sits idle? Databend employs a sophisticated, multi-level task queue system with work-stealing.
Imagine a restaurant kitchen with multiple chefs (worker threads). Instead of a single ticket rail for all orders, there are two:
- : The "Now Frying" rail. Chefs grab their next task from here.current_tasks
- : The "Orders Up" rail. New tasks generated during cooking (e.g., anext_tasksfinding it needs to read another table) are placed here.JOIN
This double-buffering system prevents chaos. When the "Now Frying" rail is empty, the manager shouts "Swap!", and the "Orders Up" rail becomes the new "Now Frying" rail. This ensures that newly created work is distributed fairly in the next wave, preventing starvation.
But what if one chef finishes their tasks while others are still busy? This is where work-stealing comes in. An idle chef can peek at another chef's task list and "steal" a waiting task.
Here’s a simplified look at the Rust code that makes this happen:
// When a worker thread is idle, it calls this function to find more work.
pub fn steal_task_to_context(...) {
let mut workers_tasks = self.workers_tasks.lock();
// 1. Try to grab a task from the global "current_tasks" queue.
if let Some(task) = workers_tasks.current_tasks.pop_task(...) {
// Found a task!
context.set_task(task);
// 2. Proactively wake up another sleeping worker if there's more work to do.
// This creates a chain reaction to quickly ramp up parallelism.
if !workers_tasks.current_tasks.is_empty() && ... {
// Smartly wakes up an adjacent worker for better cache performance.
let wakeup_worker_id = workers_tasks.current_tasks.best_worker_id(...);
workers_tasks.workers_waiting_status.wakeup_worker(wakeup_worker_id);
}
return;
}
// 3. If "current_tasks" is empty, maybe it's time to swap with "next_tasks".
if workers_tasks.current_tasks.is_empty() && !workers_tasks.next_tasks.is_empty() {
workers_tasks.swap_tasks();
// After swapping, the worker can try to steal again.
return;
}
// 4. No work anywhere. The worker goes to sleep until woken up by another thread.
workers_tasks.workers_waiting_status.wait_worker(...);
}
Critical implementation details:
- Epochs: Tasks are tagged with an "epoch" (the time slice they belong to) to ensure they are executed in the correct order.
- Cache Locality: When waking up another thread, the system prefers an adjacent worker ID (). This increases the chance that the necessary data is already in the CPU's L1/L2 cache, avoiding slow trips to main memory.worker_id + 1
- Minimal Locking: The lock on the task queue is released before waking up another thread, reducing contention and keeping the system running smoothly.
Distributed Query Execution: Turning the Network into a Port
Databend's architecture truly shines when scaling from a single machine to a distributed cluster. The magic lies in a simple but powerful abstraction: treating the network as just another port connection. This makes network communication transparent to the processors, allowing the same execution logic to work locally and across a fleet of servers.

The Blueprint for Distributed Data Flow
Imagine a logistics network. Sending a package to a different department in the same building is simple. Sending it to a warehouse across the country is more complex, requiring special packaging and handling.
Databend's executor abstracts this complexity away. For a processor, sending data is always the same. Behind the scenes, the system chooses the right "shipping method":
-
Local Transfer: A direct, in-memory connection between two processors.
[Processor] → [Port] → [Processor] -
Network Transfer: The data is handed to a specialized pair of processors that act as a network shipping/receiving department.
[Processor] → [Port] → [ExchangeSink] ═══✈️ network ✈️═══> [ExchangeSource] → [Port] → [Processor] -
: Packages the data, serializes it, and sends it over the network.ExchangeSink
-
: Receives the data from the network, deserializes it, and places it into a local port for the next processor.ExchangeSource
Anatomy of a Distributed Query
Let's trace a distributed
SUM()
-- Executed on the coordinator node
SELECT SUM(number) FROM numbers(10);
The coordinator's execution graph reveals how it orchestrates the work:

Exchange Implementation Details
The
ExchangeSourceReader
event()
// The processor for receiving data from the network.
impl Processor for ExchangeSourceReader {
fn event(&mut self) -> Result<Event> {
// Standard backpressure: if the next operator is busy, we wait.
if !self.output.can_push() {
return Ok(Event::NeedConsume);
}
// If we have data buffered from the network, push it downstream.
if !self.output_data.is_empty() {
let data = std::mem::take(&mut self.output_data);
self.output.push_data(Ok(data));
return Ok(Event::Sync); // We can work immediately.
}
// If we have no buffered data and the stream isn't finished,
// we need to wait for data from the network.
if !self.finished.load(Ordering::SeqCst) {
return Ok(Event::Async); // Tell the scheduler we're doing I/O.
}
Ok(Event::Finished)
}
// The scheduler runs this on the I/O pool when event() returns Async.
async fn async_process(&mut self) -> Result<()> {
// Wait for the next data packet to arrive from the network.
if let Some(data) = self.flight_receiver.recv().await? {
self.output_data.push(data);
}
Ok(())
}
}
Its counterpart, the
ExchangeSink
flight_sender
The Lingua Franca: Apache Arrow Flight
To move data efficiently between nodes, you need a common language. Databend uses Apache Arrow Flight RPC Protocol, a high-performance data transfer framework built for columnar data.
Instead of converting rows to JSON or another text format (which is slow), Apache Arrow allows Databend to send entire
DataBlock
// The data packet sent over the network
pub enum DataPacket {
// Schema and compression info
Dictionary(FlightData),
// The actual columnar data block
RecordBatch(FlightData),
// Metadata about the query fragment
Fragment(FragmentData),
}
This is like shipping a fully assembled product instead of a box of parts and an instruction manual. It dramatically reduces serialization/deserialization overhead and is a key reason for Databend's high-performance distributed execution.
The Payoff: A Purpose-Built Executor for the Cloud
By weaving together asynchronous I/O, a hybrid push/pull event model, and transparent parallelism, Databend's executor delivers an architecture that is not just adapted for the cloud, but born in it. This design isn't a collection of theoretical concepts; it's a pragmatic solution that directly translates into tangible benefits for anyone running analytics at scale.
Here’s how this new model solves the core challenges of cloud data warehousing:
-
Maximum CPU Utilization, Minimum Cost: The asynchronous, event-driven core ensures that CPU cores never wait for slow S3 I/O. By treating I/O as just another event, the scheduler keeps processors constantly fed with work, pushing CPU utilization above 95% in production workloads. You pay for compute, and you get to use all of it.
-
Rock-Solid Stability at Any Scale: The built-in, decentralized backpressure mechanism (
) acts as an automatic safety valve. It gracefully handles "traffic jams" in the data pipeline, preventing the memory explosions that plague traditional push-based systems. This allows Databend to run massive, complex queries without falling over.NeedConsume -
Fluid, Dynamic Adaptation: The executor isn't rigidly a "pull" or "push" system. It's both. It dynamically switches between
(pull) andNeedData(push) behaviors based on the real-time state of the pipeline. This adaptability ensures optimal performance across a wide variety of query patterns, from I/O-heavy scans to CPU-bound transformations.Sync -
Frictionless Parallelism: By duplicating pipelines and using lock-free communication, the engine scales almost linearly across multiple cores and nodes. Adding more compute power results in a direct, predictable increase in query speed, without the bottlenecks and contention that limit older architectures.
In conclusion, the journey to build a stateless MPP query engine from scratch in Rust was driven by a single imperative: to build a system that works with the grain of the cloud, not against it. The result is an executor that is resilient, efficient, and powerful, capable of delivering interactive query performance on virtually limitless data.
Part 5: Advanced Patterns and Production Lessons
With the foundation of our actor model in place, let's explore the advanced patterns and practical guidelines that are critical for achieving high performance and stability in a real-world, cloud-native query engine.
Pattern 1: Consumer-Driven Bounded Prefetch
To hide S3's high latency, we must prefetch data before it's needed. However, prefetching too aggressively can easily lead to out-of-memory errors. The key is to bound the prefetch depth and have it driven by the consumer, which creates natural backpressure.
// A simplified prefetcher that links consumption to fetching
struct PrefetchingSource {
output_port: OutputPort,
prefetch_buffer: Option<DataBlock>,
async_task: Option<JoinHandle<DataBlock>>, // Handle to the async fetch task
}
impl PrefetchingSource {
fn event(&mut self) -> Event {
// 1. If downstream is busy, wait. (This is backpressure)
if !self.output_port.can_push() {
return Event::NeedConsume;
}
// 2. If we have a completed prefetch, push it to the consumer.
if let Some(block) = self.prefetch_buffer.take() {
self.output_port.push_data(block);
// And only now, immediately start fetching the *next* block.
self.start_prefetch();
return Event::Async;
}
// ...
}
}
Key Insight: A new prefetch operation is only triggered after the previous one has been consumed. This simple rule prevents the prefetcher from running too far ahead of the rest of the pipeline.
Pattern 2: Memory-Aware Scheduling & Adaptive Parallelism
In a stateless architecture without local disk for spilling, memory is the most critical and limited resource. The scheduler must be memory-aware.
- Memory Budgeting: The executor reserves a memory headroom (e.g., 20%) and requires each operator to provide a rough estimate of its memory usage. Processors are only scheduled if they fit within the global budget.
- Adaptive Parallelism: The query pipeline can be dynamically resized. For I/O-bound stages, parallelism can be increased to saturate network bandwidth. For CPU-bound stages, it can be scaled down to match the number of available cores, preventing unnecessary thread contention.
// The pipeline can be dynamically resized based on the workload
if stage.is_io_bound() {
pipeline.resize(parallelism * 2);
} else if stage.is_cpu_bound() {
pipeline.resize(num_cpus::get());
}
Key Lessons Learned in Production
Running this architecture at scale revealed several crucial insights:
- Decompression is a Bottleneck: The CPU cost of decompressing formats like ZSTD is significant and can become a bottleneck if not properly parallelized on the CPU-pool.
- Work Stealing is Vital for Balance: Especially at the start of a query, a work-stealing scheduler (where idle threads "steal" tasks from busy ones) is essential for balancing the load across all available cores.
- Lock-Free is Non-Negotiable: The ultimate goal must be a lock-free design where each core operates independently. Any contention on shared locks becomes a major bottleneck under high parallelism.
- Prefetch Must Be Interruptible: If a downstream operator finishes or errors, any in-flight prefetch requests for it must be immediately cancelled to prevent resource leaks.
Practical Guidelines for Cloud-Native Engines
Based on Databend's experience, here are some hard-won heuristics:
- Prefetch Depth: Keep it small, typically 3-5 data blocks maximum per pipeline.
- I/O Thread Pool: A modest number of threads (e.g., 16) is sufficient to manage thousands of concurrent S3 requests without overwhelming the service.
- Memory Reservation: Always keep a 20% buffer for system overhead and unexpected spikes.
- Request Batching: To minimize S3's per-request costs, merge small file reads into larger, single requests whenever possible.
- Retry Strategy: Implement an exponential backoff strategy (e.g., 3-5 retries) to handle the transient network failures common in cloud environments.### Conclusion: A New Blueprint for the Cloud
Final Thoughts
Building a high-performance query engine on cloud object storage is not about patching old models; it's about embracing a new set of first principles. Traditional architectures, designed for low-latency local disks, are fundamentally broken by the realities of S3.
The journey through Databend's executor reveals a new blueprint: an event-driven actor model that transforms high latency from a performance bottleneck into an opportunity for massive concurrency. By combining asynchronous I/O, explicit backpressure, and lock-free communication, this architecture keeps expensive CPU resources fully utilized, even while waiting for data from across the network.
This represents a strategic trade-off: we exchange the raw, predictable speed of local storage for the immense operational leverage of the cloud—unlimited scale, unparalleled resilience, and true pay-for-use economics. The patterns explored here are more than just an engineering exercise; they are a glimpse into the future of data analytics, where systems are designed from the ground up to be truly cloud-native.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

