


We're excited to bring you the latest updates, new features, and improvements for August 2024 in Databend! We hope these enhancements are helpful, and we look forward to your feedback.
Kafka Connect Sink Connector Plugin
We introduced a new way to connect Kafka to Databend with databend-kafka-connect, a Kafka Connect sink connector plugin. This plugin supports both Append Only and Upsert write modes and can automatically create target tables in Databend based on the data schema. For more details, check out the documentation: https://docs.databend.com/guides/load-data/load-db/kafka#databend-kafka-connect
To get hands-on experience with loading Kafka messages into Databend, explore these tutorials:
Full-Text Fuzzy Search
The full-text search functions MATCH and QUERY can now include the following options in the syntax to allow for fuzzy search:
- : Allows matching terms within a specified Levenshtein distance.
fuzziness - : Specifies how multiple query terms are combined. Can be set to OR (default) or AND. OR returns results containing any of the query terms, while AND returns results containing all query terms.
operator - : Controls whether errors are reported when the query text is invalid. Defaults to false. If set to true, no error is reported, and an empty result set is returned if the query text is invalid.
lenient
Here are some quick examples:
When matching the query term "box",
fuzziness=1
SELECT id, score(), content FROM t WHERE match(content, 'box', 'fuzziness=1');
With operator=AND, the following query requires both "action" and "works" to be present in the results:
SELECT id, score(), content FROM t WHERE query('content:action works', 'fuzziness=1;operator=AND');
Due to
fuzziness=1
Enhanced FUSE_STATISTIC Function
The FUSE_STATISTIC function now includes a new statistical feature: histogram. This new addition provides detailed insights into the distribution of data within each column.
- : The identifier for the bucket.
bucket id - : The minimum value within the bucket.
min - : The maximum value within the bucket.
max - (number of distinct values): The count of unique values within the bucket.
ndv - : The total number of values within the bucket.
count
Here's an example:
SELECT * FROM FUSE_STATISTIC('default', 'sample');
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ column_name │ distinct_count │ histogram │
├─────────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ name │ 6 │ [bucket id: 0, min: "Alice", max: "Alice", ndv: 1.0, count: 1.0], [bucket id: 1, min: "Bob", max: "Bob", ndv: 1.0, count: 1.0], [bucket id: 2, min: "Charlie", max: "Charlie", ndv: 1.0, count: 1.0], [bucket id: 3, min: "Diana", max: "Diana", ndv: 1.0, count: 1.0], [bucket id: 4, min: "Eve", max: "Eve", ndv: 1.0, count: 1.0], [bucket id: 5, min: "Frank", max: "Frank", ndv: 1.0, count: 1.0] │
│ age │ 5 │ [bucket id: 0, min: "25", max: "25", ndv: 1.0, count: 1.0], [bucket id: 1, min: "28", max: "28", ndv: 1.0, count: 1.0], [bucket id: 2, min: "28", max: "28", ndv: 1.0, count: 1.0], [bucket id: 3, min: "30", max: "30", ndv: 1.0, count: 1.0], [bucket id: 4, min: "35", max: "35", ndv: 1.0, count: 1.0], [bucket id: 5, min: "40", max: "40", ndv: 1.0, count: 1.0] │
│ user_id │ 6 │ [bucket id: 0, min: "1", max: "1", ndv: 1.0, count: 1.0], [bucket id: 1, min: "2", max: "2", ndv: 1.0, count: 1.0], [bucket id: 2, min: "3", max: "3", ndv: 1.0, count: 1.0], [bucket id: 3, min: "4", max: "4", ndv: 1.0, count: 1.0], [bucket id: 4, min: "5", max: "5", ndv: 1.0, count: 1.0], [bucket id: 5, min: "6", max: "6", ndv: 1.0, count: 1.0] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Databend Cloud Enhancements
We've enhanced your Databend Cloud experience, so you can enjoy improved features and performance.
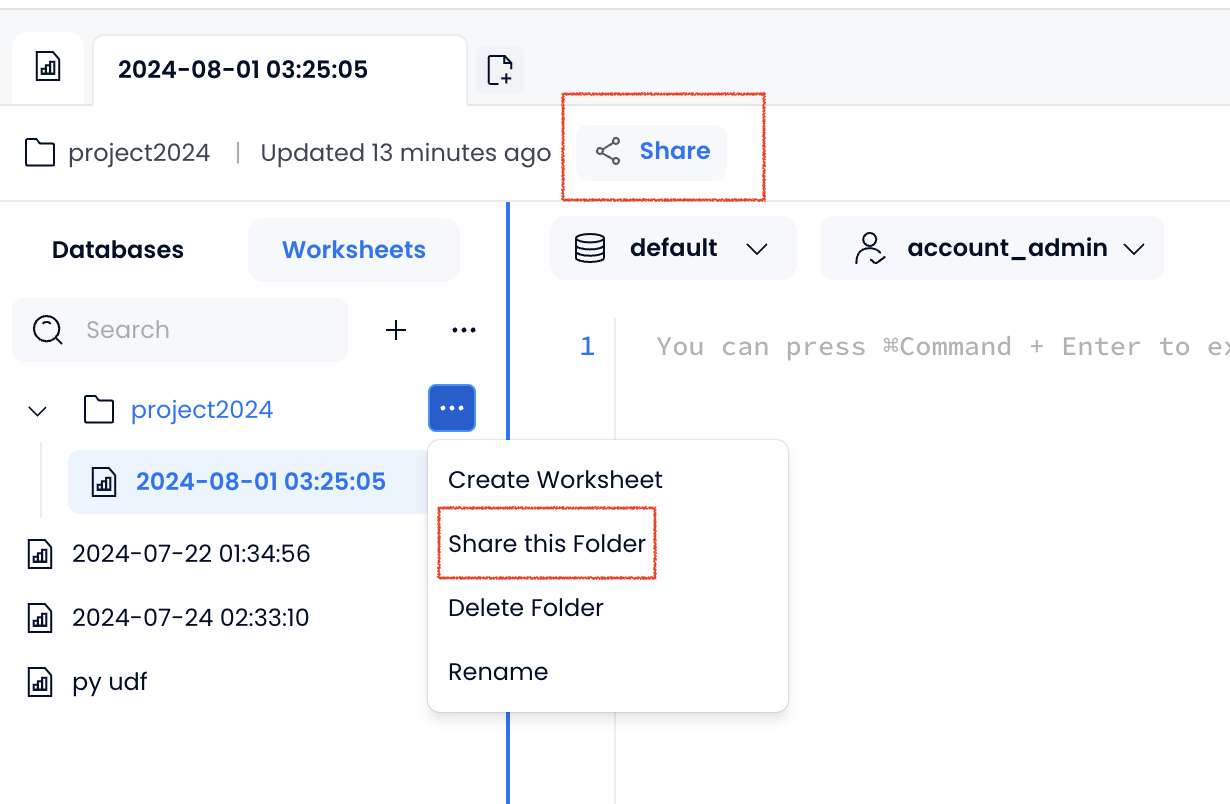
- You can now share your worksheets with everyone in your organization or specific individuals.
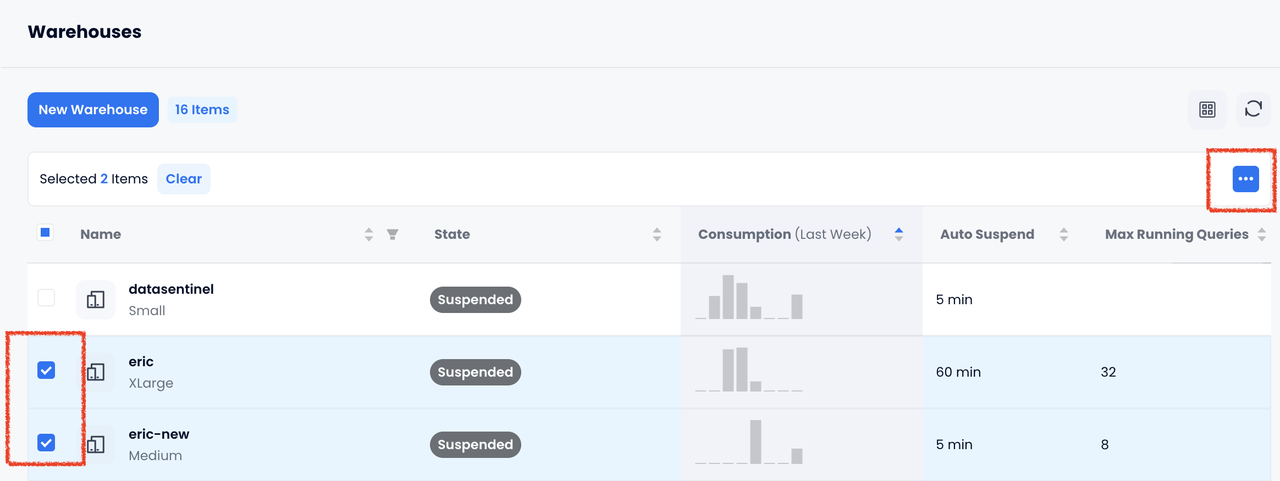
- You can now perform bulk restart, bulk suspend, bulk resume, and bulk delete operations on warehouses.
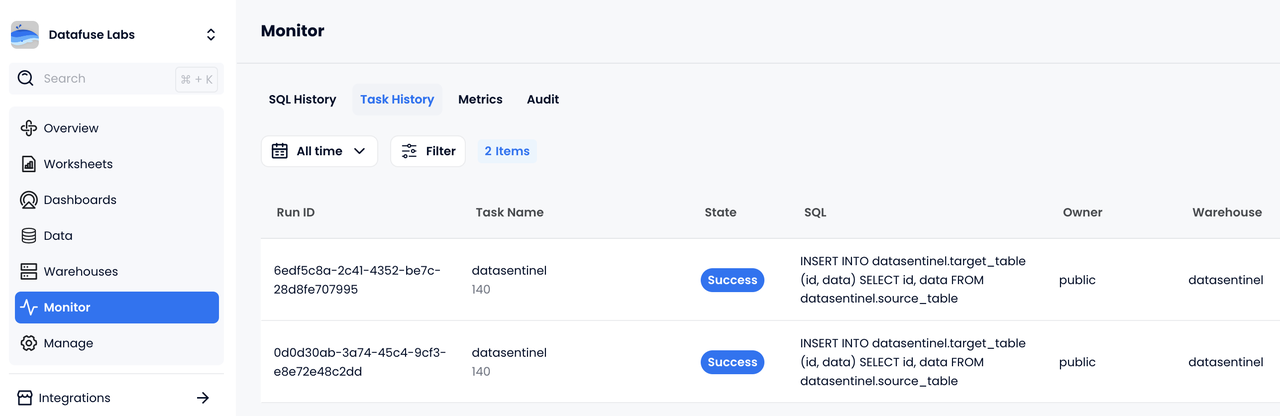
- You can now view the results of running tasks by navigating to Monitor > Task History in Databend Cloud.
New SQL Functions
We added new functions to enhance your SQL capabilities:
- JQ: Allows you to apply jq filters to JSON data stored in Variant columns.
- JSON_OBJECT_AGG: Converts key-value pairs into a JSON object.
- JSON_ARRAY_AGG: Converts values into a JSON array while skipping NULLs.
- MONTHS_BETWEEN: Returns the number of months between two dates.
Performance Improvements
Discover our latest enhancements that boost Databend's speed, accuracy, and resilience.
- Global Plan Caching: We introduced plan caching to speed up repeated queries with cached and reusable query plans for faster performance.
- Accurate Decimal Calculations: We fixed an issue with decimal multiplication, ensuring your calculations are always precise.
- Faster UDF Execution: We optimized the JavaScript runtime for user-defined functions, reducing delays and improving execution speed.
- Robust Network Operations: We improved how Databend handles network errors, making it more resilient in distributed environments.
- Improved JOIN Performance: We enhanced the efficiency of join operations, particularly in clustered modes, resulting in faster query processing and reduced latency in complex queries.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

