


In recent years, the notion that "big data is dying" seems to be gaining traction. Some say the big data craze has faded, while others lament the shrinking job opportunities, the increasing complexity of platforms, and the growing intricacy of business demands. But does this really mean big data is dying?
I don’t think so. In my view, what’s truly dying is not big data itself, but rather the outdated "dragon-slaying techniques" that no longer have any "dragons" to slay. The "dragon" has evolved, while our weapons remain stuck in the past. Technology needs to evolve, architectures need to be restructured, and capabilities need to be upgraded.
To understand the current state and trends of big data, we must first examine how it has evolved step by step. The development of big data can be divided into three stages:
Stage Ⅰ: Traditional Hadoop — The First Generation of "Siloed" Big Data Platforms
The earliest big data platforms were primarily built around Hadoop, with the Lambda architecture (offline + real-time) serving as the de facto industry standard at the time. However, in practice, I deeply realized that big data platforms at this stage were still extremely difficult to use, requiring substantial manpower and resource investment. The systems built were hard to truly commercialize, functioning merely as collections of offline components.
Back then, technical teams would present various Hadoop + Hive + Spark architecture diagrams to their bosses, pitching grand visions of the future. Riding the wave of the “data middle platform” narrative, they expanded their teams, assembling ambitious big data teams of fifty people, determined to stack up the platforms with great enthusiasm.
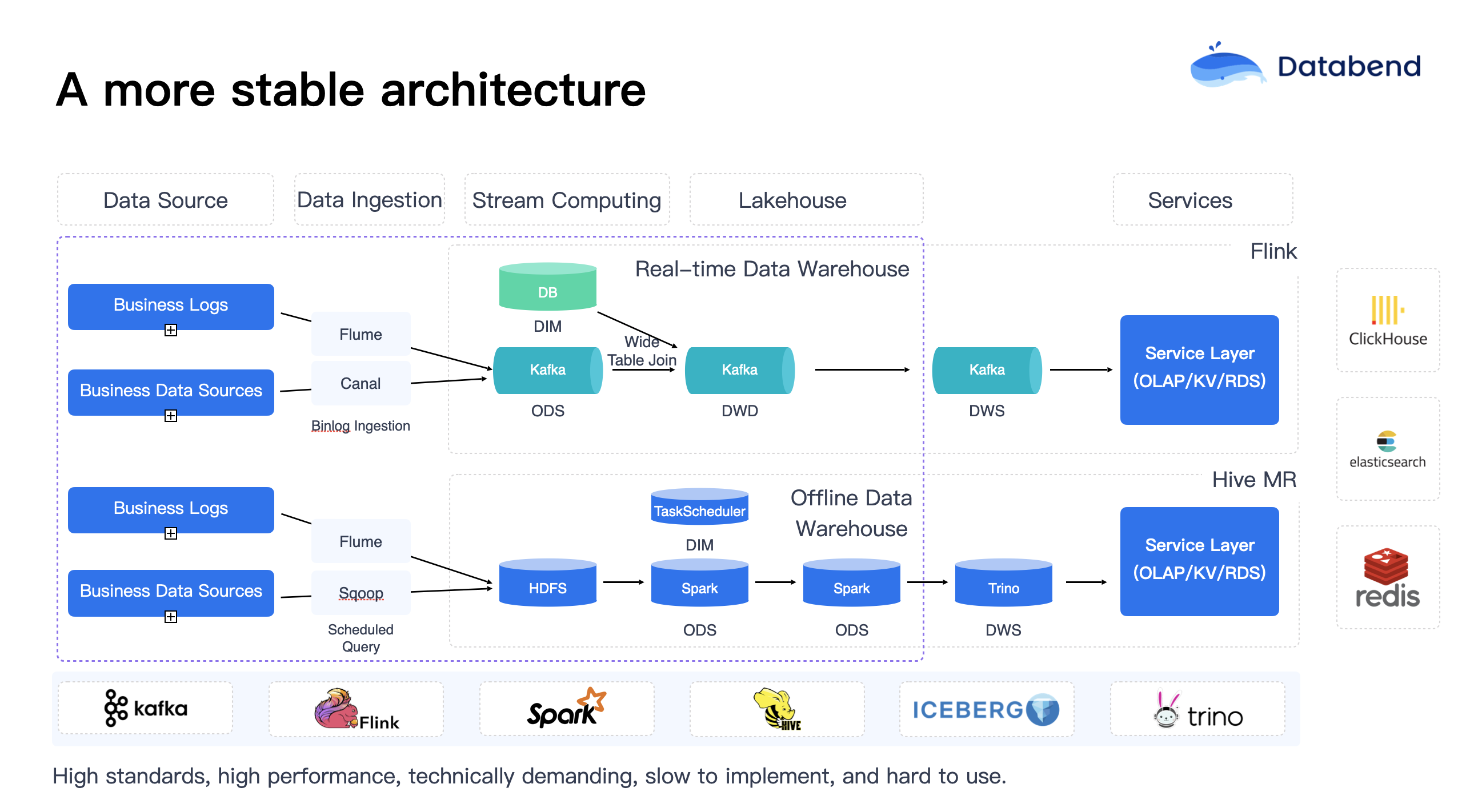
However, reality quickly delivered a harsh wake-up call:
- Data inconsistencies were rampant, and the only consolation to the boss was, “A discrepancy of one or two records in massive datasets doesn’t affect usage; this system isn’t tied to core business operations.”
- When data was found to be written incorrectly, it couldn’t be updated—entire partitions had to be deleted and rewritten.
- Costs remained stubbornly high because data often had to be stored in duplicate.
- Despite boasts about how powerful the big data platform was, a simple query could crash the entire system, just because the query didn’t include a partition key.
- In the early days, the platform handled 1 billion rows per month with reasonably designed partitions. But when daily data volumes hit 2 billion, the system began to lag severely. By the time data reached the trillion scale, the original team had already jumped ship, leaving the platform to be scrapped and rebuilt.
- The platform consisted of numerous components (at least 30 or more), and upgrading any single component was enough to bring the entire system down.
- The “siloed” architecture resulted in a forest of isolated systems, with each new “silo” introducing fresh security vulnerabilities that could destroy the platform.
- SQL execution plans took several minutes to generate, rendering them practically unusable (due to excessive partitions overwhelming metadata).
- When the boss casually requested, “Just deduplicate the data,” the entire team wanted to quit. (Back then, only the ODS layer of a certain major platform was barely functional.)
- … The list of such frustrating examples is endless.
It’s fair to say that big data platforms at this stage kept bosses up at night. Practice proved that this architecture not only failed to support business needs but could also lead the company’s big data strategy into a dead end. Big data engineers spent most of their time using Spark to load data into Hadoop, performing cleaning and governance, and preparing data for upstream data development and utilization teams. Critically, at this stage, the data development and utilization teams barely dared to speak up, often finding themselves in a disadvantaged position.
Stage Ⅱ: Data Lake + Lakehouse Integration — Component "Slimming," but Architectural Complexity Remains High
The painful lessons from the first generation of big data platforms forced a restructuring of architectures. Data lake architectures, represented by Apache Iceberg and Delta Lake, emerged to replace the closed Hadoop ecosystem, enabling a “lakehouse” solution with transaction support, unified metadata, and unified storage.
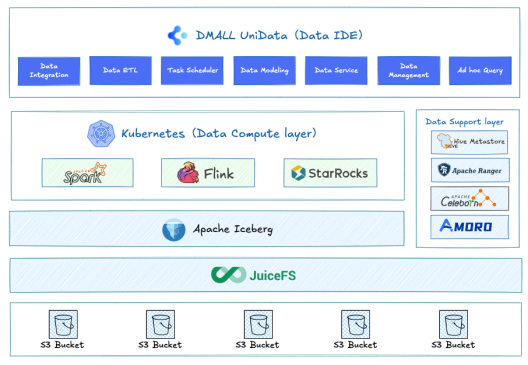
At this stage, technical teams began attempting to simplify components and reduce deployment complexity. We started introducing data lakes, persisting data in Iceberg format (ODS), supporting statistical read/write operations with Spark and Flink, and reducing the number of components from over 30 to around 10. The size of big data teams also shrank from over 50 people to about 10. During this phase, the work of big data teams primarily included:
- Learning Spark scheduling tasks to clean up historical versions of Iceberg.
- Learning Spark scheduling tasks to perform Iceberg’s compact operations.
- Learning Spark scheduling tasks to handle Iceberg’s Z-order processing.
- Learning to use Shuffle service invocations.
- Managing permissions for the integration of various open-source components.
- Developing an SQL Gateway to route SQL queries to three backend compute engines based on query characteristics.
- Presenting the boss with a “beautifully designed, powerful” platform.
At this stage, it was possible to paint an optimistic picture for the boss:
- Support for ACID transactions.
- Implementation of unified metadata management.
- Support for unified storage.
However, bosses often raised doubts: “Wait a minute, this platform still requires at least 10 people. Wouldn’t it be better to have those 10 people work on business operations instead?”
In reality, most companies built their big data platforms on this foundation. Although the platform slimmed down, with team sizes reduced from 50 to 10 and component counts from 30 to 10, the underlying complexity remained excessively high, making it difficult for most enterprises to fully implement and utilize.
If such a platform could withstand data volumes reaching the trillion level, it would be considered exceptionally fortunate. Otherwise, big data developers would have to “take the fall.” As a big data engineer working on such platforms, it’s critical to understand its positioning: single-table data should ideally not exceed 10 billion records, and the entire database should be kept under 10,000 tables. Beyond these limits, no amount of Spark tasks can save the day, and overtime becomes inevitable.
Stage Ⅲ: Cloud-Native, Disrupting the "**Big Data** Engineer" (Current)
Entering the third stage, particularly in the gaming industry, large gaming companies launch new business initiatives weekly, followed by a flood of data analysis demands. In such scenarios, using the solutions from Stage Ⅱ, you’d find yourself building a new platform for each initiative, with any issue leading to all-night overtime. In the gaming industry, every moment translates to money, and every step impacts the year-end bonuses of the team. Traditional big data solutions can no longer meet business demands:
- Data needs to be ingested at second-level latency.
- Systems must support tens of thousands of streaming computations.
- There are massive demands for data mining.
At this point, cloud-native platforms like Snowflake and Databend—offering pay-as-you-go pricing, integrated batch and streaming processing, and full SQL expressiveness—have emerged to meet these needs.
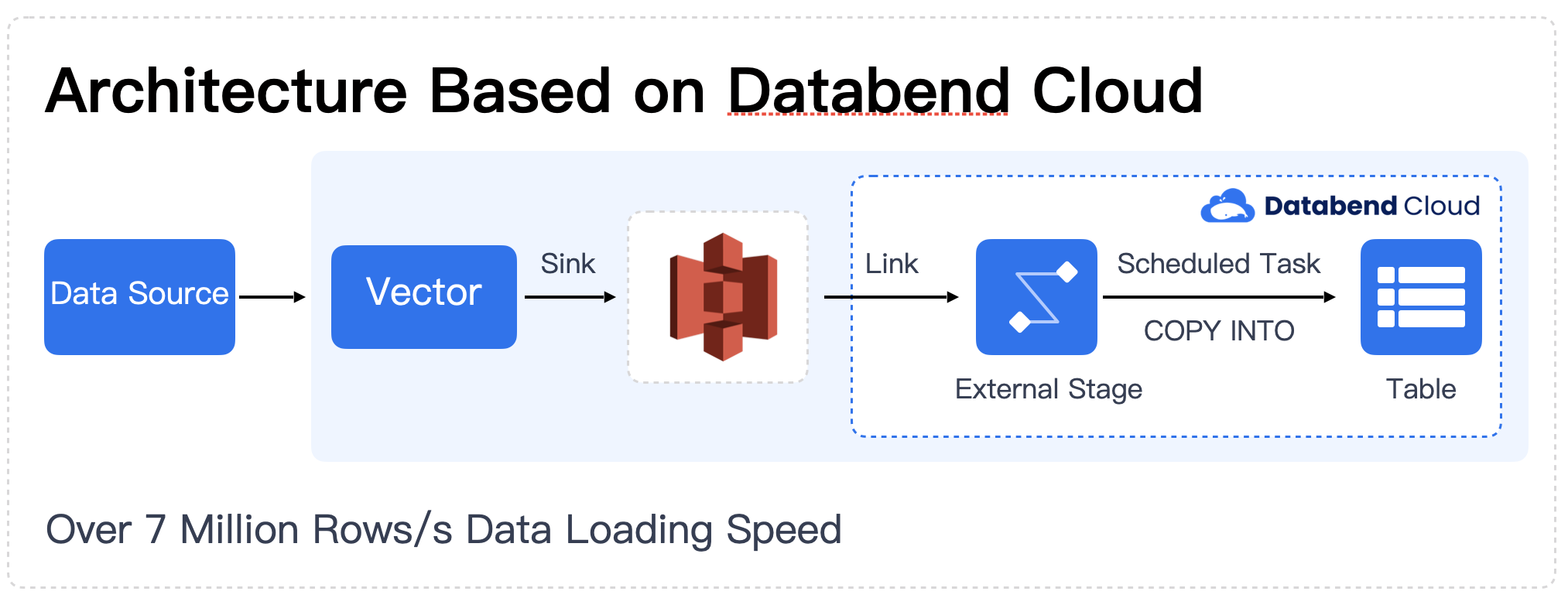
They have transformed big data platforms: files like CSV, NDJSON, Parquet, ORC, and others stored in S3 can now be queried directly using standard SQL. Without relying on a Spark team for preprocessing, ETL engineers can complete data ingestion tasks that used to take two days in just half an hour.
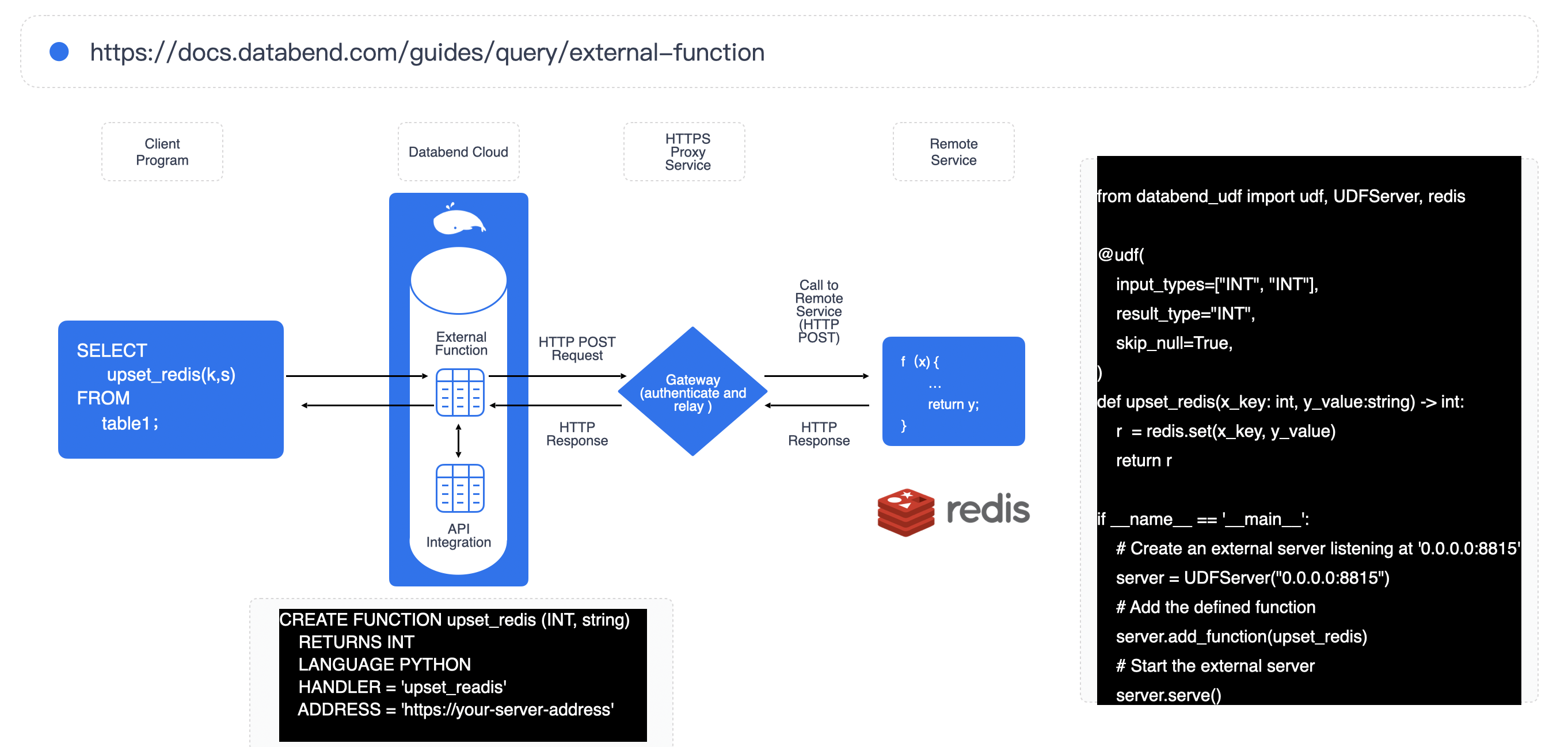
If you know some Python, you can also leverage products like Databend, which support external UDFs, to implement table-level change capture and replace traditional Flink jobs. In the gaming industry, for example, tasks that output detailed match data immediately after a game ends can now be handled this way. Workloads that used to require dozens of Flink clusters can now be completed in just half a day — with the added benefit of elastic scaling.
At this point, we start to see the role of "data preparation engineers" disappearing, and traditional "data warehouse platform specialists" gradually becoming marginalized. Big data has entered a new stage: lightweight platforms, expressive data modeling, and strong business understanding.
Today, products like Snowflake, Databricks, and Databend offer robust solutions in this area.
Summary
There’s still plenty of work across today’s big data ecosystem, with roles that include but are not limited to:
- Data preparation engineers (formerly known as "data movers") — increasingly platformized or SaaS-based;
- ETL engineers;
- BI and data analysts (who might still track tasks in Excel daily, or use Text2SQL tools for assistance);
- Data quality and lineage engineers (platformized & SaaS-based);
- Algorithm and machine learning engineers;
- Scheduling platform developers (SaaS);
- Data pipeline developers (SaaS — "data sync" roles rebranded);
- Data visualization engineers (platformized & SaaS-based);
- Data platforms (large-scale big data systems built on stacks of concepts, now shifting toward "Data + AI");
- Business-focused data analysts (for example, analyzing the impact of a $100,000 marketing spend to optimize future campaigns);
- Operators and decision-makers who monetize and drive actions from data insights.
In fact, demand for big data talent remains strong — it’s just that the industry now calls for more specialized skills. Traditional "data mover" roles are indeed shrinking, as simpler tools and platforms have made much of that work obsolete.
If you’re considering a career in big data, there's still huge potential. Here's my personal view on a learning and growth path:
- Start as an ETL engineer or data ingestion engineer (focus on low-code tools + SQL);
- Grow into specialized engineering roles — such as working on data synchronization tools, scheduling platforms, or visualization systems;
- Dive deeper into the core internals — storage, algorithms, SQL engines, and compilation — all excellent long-term directions.
Big data isn’t dying — the infrastructure era is simply ending, and we’re entering the smart operations era. In the future, it won't be about who can stack more components — it’ll be about who can create data value faster and more cost-effectively.
I transitioned from OLTP systems to big data infrastructure, and I’m currently the Co-founder and Head of Ecosystem at Databend Labs. This year marks my fourth year in the big data field. Although I’m still a newcomer in many ways, I’ve already deeply felt the tremendous changes and limitless opportunities in this industry. I warmly welcome more big data professionals to connect, share, and grow together.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

