

That "simple" data request is never simple.
You get the ticket. It's from the marketing team, and they need sales data to analyze a campaign. It seems easy enough, until you remember what the sales table actually looks like.
Alongside the safe columns like
product_id
region
customer_email
profit_margin
You can't give them access to the whole table.
So you're stuck. Your options are to either create a stale, messy copy of the data with the sensitive columns removed, or to go down the rabbit hole of building and maintaining a dedicated API. One path leads to data rot, the other to a project you don't have time for.
This Problem Solution Has a Name: Data Mesh
This daily friction isn't just your problem; it's a classic symptom of a centralized data architecture. A central team (like yours) owns all the data and becomes a bottleneck for every request. This slows everyone down and puts an immense burden on your team to be the gatekeeper for everything.
This is precisely the problem that the Data Mesh philosophy was created to solve.
The core idea of a Data Mesh is to stop treating data as a centralized warehouse and start treating it as a decentralized ecosystem. It has two simple principles that apply directly here:
Domain Ownership: The team that produces and understands the data (the "domain") should own it. In this case, the Sales or Operations team owns the sales data. Data as a Product: That team is then responsible for sharing their data not as a raw, messy table, but as a clean, secure, and easy-to-use "data product" for others (like the marketing team) to consume.
From Philosophy to Practice: How Do You Share a Data Product?
The idea of a "data product" is powerful, but it raises a critical question: how do you actually create and share one without adding massive engineering overhead? In the broader data landscape, two dominant philosophies have emerged:
-
The Centralized Marketplace (e.g., Snowflake's Data Cloud) This approach provides a governed, all-in-one platform where data producers can publish their data products and consumers can discover them. It’s a “walled garden”—incredibly powerful for discovery and security if everyone is on the same platform, but it inherently prioritizes a single ecosystem. Sharing data with the outside world often requires moving it.
-
The Open Sharing Protocol (e.g., Databricks' Delta Sharing) This approach focuses on creating an open, vendor-neutral standard for sharing live data. The goal is interoperability, allowing consumers to access data from their tool of choice without being locked into a specific platform. While this offers great flexibility, it can introduce complexity in managing security, permissions, and discovery across different environments.
Both models are valid attempts to solve the data sharing problem, but they often involve significant platform investment or architectural complexity. They beg the question: what if creating a secure, live, read-only data product didn't require a marketplace or a new protocol? What if it were as simple as a single command and use platform authn/authz like AWS IAM role to control access?
This is where the concept of direct data attachment comes in.
Yet Another Approach: Direct Data Attachment
Instead of relying on a dedicated sharing platform or protocol, a third approach exists: treating the data and its underlying storage as the source of truth—wherever it may be. The core idea is to create lightweight, metadata-only links to data that resides in any S3-compatible object storage, from AWS S3, Google GCS to Cloudflare R2 and MinIO.
This is the principle of direct data attachment. Rather than copying data or wrapping it in a complex sharing layer, you create a new table object in a database's catalog that simply points to the physical files of an existing table. No data is moved or duplicated. This has a few direct consequences:
- It's inherently zero-copy. The cost and complexity of creating a "shared" table are reduced to a simple metadata operation, making the process nearly instantaneous.
- Data is always live. Because the attached table is just a pointer to the original data files, any updates to the source are immediately reflected. There is no sync process or replication lag.
- Security is managed at the source. Access control can be handled by the cloud platform's native tools, such as AWS IAM roles, aligning with existing security practices without requiring new credentials.
- Access is granular by design. The metadata link doesn't have to expose the entire table. It can be defined to include only a specific subset of columns, allowing data owners to create tailored, minimal-access views that fulfill the principle of least privilege.
This method provides a simple, direct way to create the "data products" envisioned by the Data Mesh philosophy. A team can create a secure, column-specific, read-only view of their data for another team, and the mechanism for doing so is a simple pointer, not a new system. Databend implements this concept through its
ATTACH TABLE
From Principle to Practice: A SQL Walkthrough
This walkthrough demonstrates how a central data team can provide tailored, secure access to a single source table for two different consumer teams.
Prerequisite: Securely Connecting to Storage
First, you need a secure way to access the data in its S3 bucket. Instead of putting credentials directly into every
ATTACH
CONNECTION
-- Create a named connection that encapsulates S3 credentials.
CREATE CONNECTION s3_central_storage
STORAGE_TYPE = 's3'
ACCESS_KEY_ID = '<your-access-key-id>'
SECRET_ACCESS_KEY = '<your-secret-access-key>';
Creating Column-Specific Views for Different Teams
Using this connection, the data team can now create multiple table pointers from the same source data, each with a different column schema.
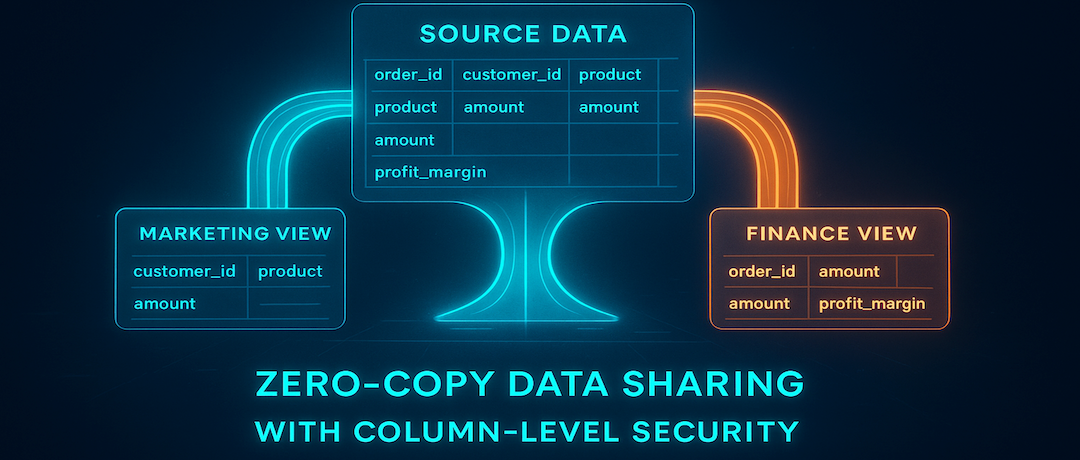
1. View for the Marketing Team: This view exposes columns relevant to campaign analysis.
-- Create a read-only table pointer for Marketing.
ATTACH TABLE marketing_view
(customer_id, product, amount, order_date)
's3://central-team-bucket/path/to/sales_transactions/'
CONNECTION = (CONNECTION_NAME = 's3_central_storage');
2. View for the Finance Team: This view exposes columns relevant to revenue tracking, while omitting PII.
-- Create another read-only table pointer for Finance.
ATTACH TABLE finance_view
(order_id, amount, profit_margin, order_date)
's3://central-team-bucket/path/to/sales_transactions/'
CONNECTION = (CONNECTION_NAME = 's3_central_storage');
As a result, two new queryable tables,
marketing_view
finance_view
s3://central-team-bucket/path/to/sales_transactions/
Conclusion
Architecturally, data sharing can be approached through different patterns, such as a unified platform, a common protocol, or by referencing data in place. Each has distinct implications for how data is managed and accessed.
The direct data attachment pattern uses a command like
ATTACH TABLE
Resources
- Databend Documentation: ATTACH TABLE: The official reference for the command.ATTACH TABLE
- Databend Documentation: CREATE CONNECTION: Learn more about creating and managing secure connections to external storage.
- Getting Started with Databend: Explore Databend and try it for yourself.
- Book a Demo with us: Schedule a demo to learn more about Databend and how it can help your organization.
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

