
Is Parquet becoming the bottleneck? Why new storage formats are emerging in 2025 (Lance, Vortex, and more)
 ZhiHanZSep 15, 2025
ZhiHanZSep 15, 2025


Parquet gave data lakes a common language: columnar layout, good compression, and fast scans. That still works well for classic analytics. But workloads have changed. We now mix wide scans with point lookups, handle embeddings and images, and run on S3-first stacks. On NVMe you want lots of tiny random reads. On S3 you want fewer, larger range requests. A format tuned for one world can feel chatty or slow in the other.
This piece doesn’t pick a winner. It shows where Parquet shines, where it fights the platform, and why formats like Lance and Vortex make different choices. Think structural indexes for O(1) lookups, SIMD‑friendly mini-blocks, and compression pipelines so fast that decompression is effectively free. The goal is simple: use the right format for the job, not one format for every job.
1. Why New Storage Formats Now?
For years, Apache Parquet has been the undisputed king of columnar storage for analytics. Yet, a new wave of specialized formats like Lance, Vortex, and proprietary native formats are emerging. This isn't just hype; it's a rational response to fundamental shifts in how we store and process data.
Three trends are driving this evolution:
-
The S3-Native Data Stack: The center of gravity for data has moved to object stores like Amazon S3. Unlike local filesystems, S3 has a distinct performance profile: high per-request latency but massive throughput. This model penalizes chatty formats that require many small I/O operations and rewards those that can issue fewer, larger, well-batched reads.
-
Evolving Workloads: The world is no longer just SQL analytics. We now have mixed-access patterns where large, full-table scans coexist with fine-grained random lookups. Furthermore, the rise of AI/ML means we're storing and analyzing multi-modal data—images, video, audio, and embeddings—alongside traditional structured data. These large binary objects have very different access patterns than typical scalar values.
-
Hardware Shifts: On one hand, NVMe SSDs have made small, random I/O operations on local machines incredibly fast, opening the door for new indexing strategies. On the other, the dominance of S3 means formats must also be optimized for a high-latency, pay-per-request environment.
The consequence is clear: there is no longer a one-size-fits-all storage format. Real-world performance is now a complex interplay between the format's design, its specific library implementation, and the underlying hardware it runs on.
2. A Parquet Primer
To understand the new formats, let's start with a simple analytical query. Imagine you have a massive table of user events and you run:
SELECT user_id, event_type
FROM user_events
WHERE event_date = '2025-09-15';
A traditional row-based database would have to read every column (
user_id
event_type
event_date
session_id
payload
user_id
event_type
event_date
This is the core principle behind Parquet's design. Its brilliance lies in a hierarchical structure built to maximize this I/O reduction and improve compression for large-scale analytical queries.
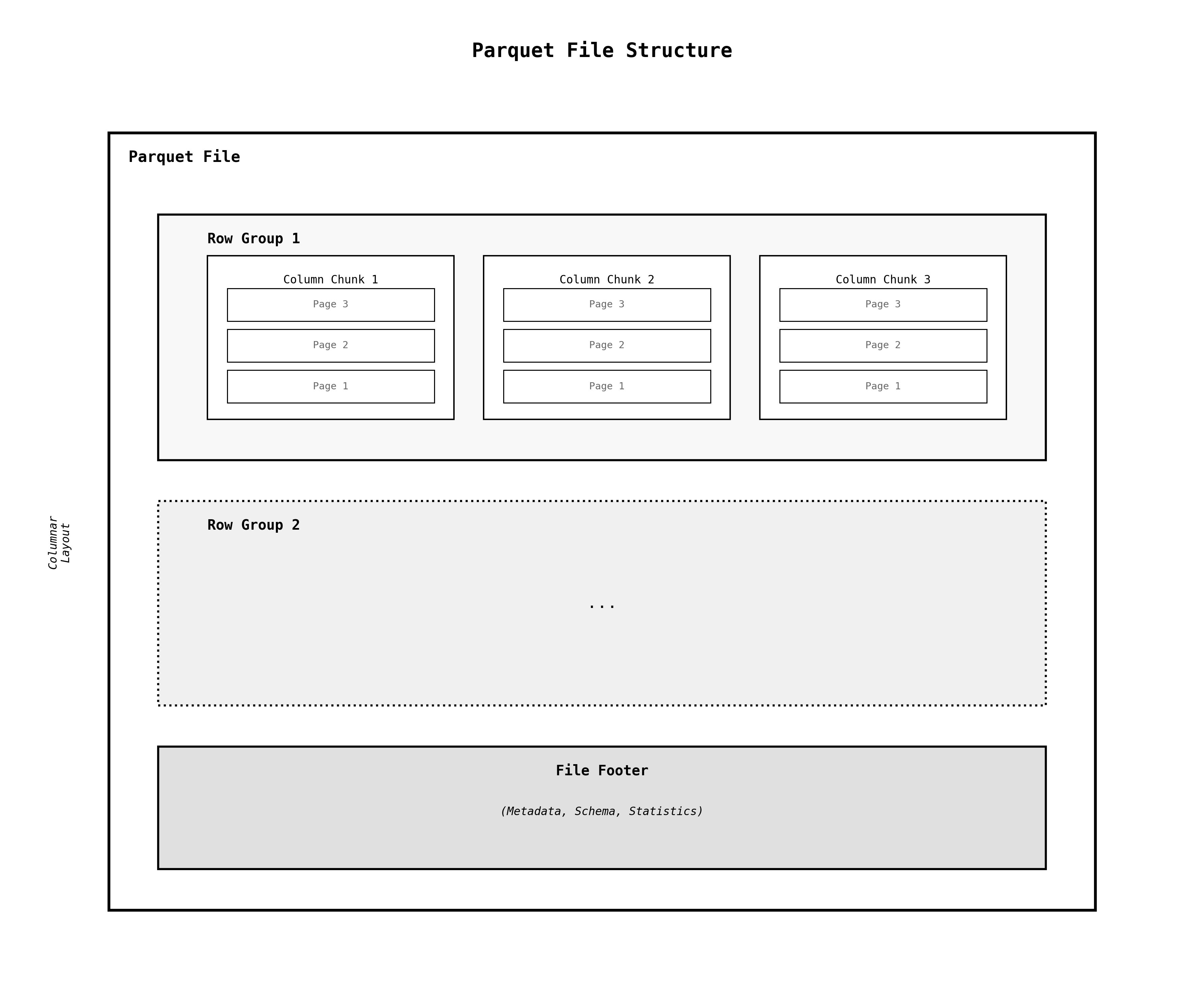
- File Structure: A Parquet file is organized into ,Row Groups, andColumn Chunks.Pages
- File: The top-level container.
- Row Group: A horizontal slice of the data (e.g., millions of rows). Data within a row group is stored in a columnar layout. This is critical for analytical queries, which typically only access a few columns from a wide table. By storing data in columns, the query engine can read only the necessary columns, dramatically reducing I/O. Furthermore, grouping similar data types together leads to much higher compression ratios.
- Column Chunk: All the data for a single column within a row group.
- Page: The smallest unit of encoding and compression within a column chunk. A page typically contains a few thousand values.
-
Metadata and Statistics: At the end of the file, a footer contains the schema and, crucially, statistics (like min/max values, null counts) for every column chunk. This allows a query engine to perform predicate pushdown—skipping entire row groups that don't contain the data needed for a query (e.g.,
).WHERE sales_date = '2024-02-15' -
Encodings and Compression: Parquet employs a two-stage process to shrink data. First, it applies a data-aware encoding to transform the data into a more compressible representation. Then, it uses a general-purpose compression algorithm on the encoded data.
Stage 1: Encodings (Data-Aware Transformation)
- Dictionary Encoding: Best for columns with low cardinality (few unique values), like a column. Instead of storingcountrya million times, Parquet builds a dictionary"United States"and stores the data as a sequence of small integers ({"United States": 0, "Canada": 1, ...}). This is a huge space saving.0, 1, 0, 0, 1, ...
- Run-Length Encoding (RLE): Ideal for sorted or repetitive data. A sequence like is stored as[A, A, A, A, B, B, C]. This is highly effective for boolean columns or columns with long stretches of identical values.(A, 4), (B, 2), (C, 1)
- Delta Encoding: Used for sequences of numbers where the differences are small, such as timestamps or sequential IDs. Instead of storing , it stores a base value ([1663200000, 1663200001, 1663200002]) and the deltas (1663200000). This transforms large numbers into a list of small, highly compressible integers.[1, 1]
Stage 2: Compression (General-Purpose Algorithm)
After encoding transforms the data into a more uniform and repetitive format, a general-purpose algorithm like ZSTD or Snappy is applied to the result. These algorithms are highly effective at finding and shrinking patterns in byte streams, completing the compression process.
- Dictionary Encoding: Best for columns with low cardinality (few unique values), like a
3. Parquet's S3-Native Reality
While Parquet is a powerful standard, its design assumptions can clash with the reality of cloud object storage.
-
Strengths: Its mature ecosystem, wide tooling support, and excellent performance on scan-heavy analytical workloads make it the default choice for interoperability.
-
Challenges on S3:
-
The "Chatty" Protocol Problem (Request Amplification): Parquet's metadata structure encourages a "chatty" interaction style that is a poor fit for high-latency object storage. A simple query can trigger a cascade of dependent I/O requests:
- Step 1: Fetch the Footer. The query engine must first read the file footer to get the schema and row group locations. (1 S3 GET request)
- Step 2: Fetch Row Group Metadata. Based on the footer's statistics, the engine identifies potentially relevant row groups and fetches their metadata. (N S3 GET requests)
- Step 3: Fetch Page Indexes. Within those row groups, it reads the page index for each required column to get page-level statistics. (M S3 GET requests)
- Step 4: Fetch Data Pages. Finally, it fetches the actual data pages that need to be scanned. (P S3 GET requests)
For a selective query on a large, multi-row-group file, the total number of sequential, high-latency requests (1 + N + M + P) can easily number in the dozens or hundreds, dominating the query time before a single byte of data is even processed.
-
Metadata Bloat: To improve data skipping, Parquet introduced page-level statistics. However, for columns with high cardinality (many unique values), this metadata can become enormous. It's not uncommon for the metadata to grow to tens of megabytes, all of which must be downloaded and parsed just to plan the query, further exacerbating the initial I/O cost.
-
-
Databend’s S3-Native Approach: To mitigate these issues, query engines like Databend employ several strategies when working with Parquet on S3:
- Async I/O and Prefetching: Use modern libraries (like the Rust crate) to issue I/O requests asynchronously and prefetch necessary metadata and data pages in parallel.parquet
- Coarse-Grained Structure: Write Parquet files with only one large row group. This reduces the amount of metadata that needs to be read and managed.
- Externalized Metadata: Instead of relying solely on the Parquet footer, store higher-level table and index metadata in a separate, dedicated metadata service that can be cached in memory.
- Smart Defaults: Use ZSTD compression by default and disable most encodings unless they provide a clear benefit, optimizing the trade-off between I/O savings and CPU decompression cost.
- Async I/O and Prefetching: Use modern libraries (like the Rust
4. Lance: A Cloud-Native Format for Fast Random Access and Comparable Scan Performance on NVMe
Parquet is the undisputed champion of large-scale analytical scans, but it has an Achilles' heel: random access. Retrieving a single row from a column of variable-width data—like the 10,000th image or the 500th text document—requires reading and decompressing all preceding data. This O(n) operation is prohibitively slow for modern AI and analytics workloads that depend on fast, random lookups.
For example, when training a model on a video dataset, you often need to fetch random frames from different videos. If the dataset is in Parquet, fetching frame
i
0
i-1
Lance was designed to solve this exact problem. Inspired by concepts from Google's Procella, it introduces structural encodings that make random access an O(1) operation. This is achieved through a design that is simultaneously optimized for two critical environments:
- Cloud-Native Performance (S3): By enabling targeted reads of specific byte ranges, Lance avoids the "chattiness" of Parquet and minimizes the number of high-latency S3 requests.
- Local Speed (NVMe): On modern NVMe SSDs, the ability to perform a direct lookup translates to near-instantaneous data retrieval, fully leveraging the high IOPS of local hardware.
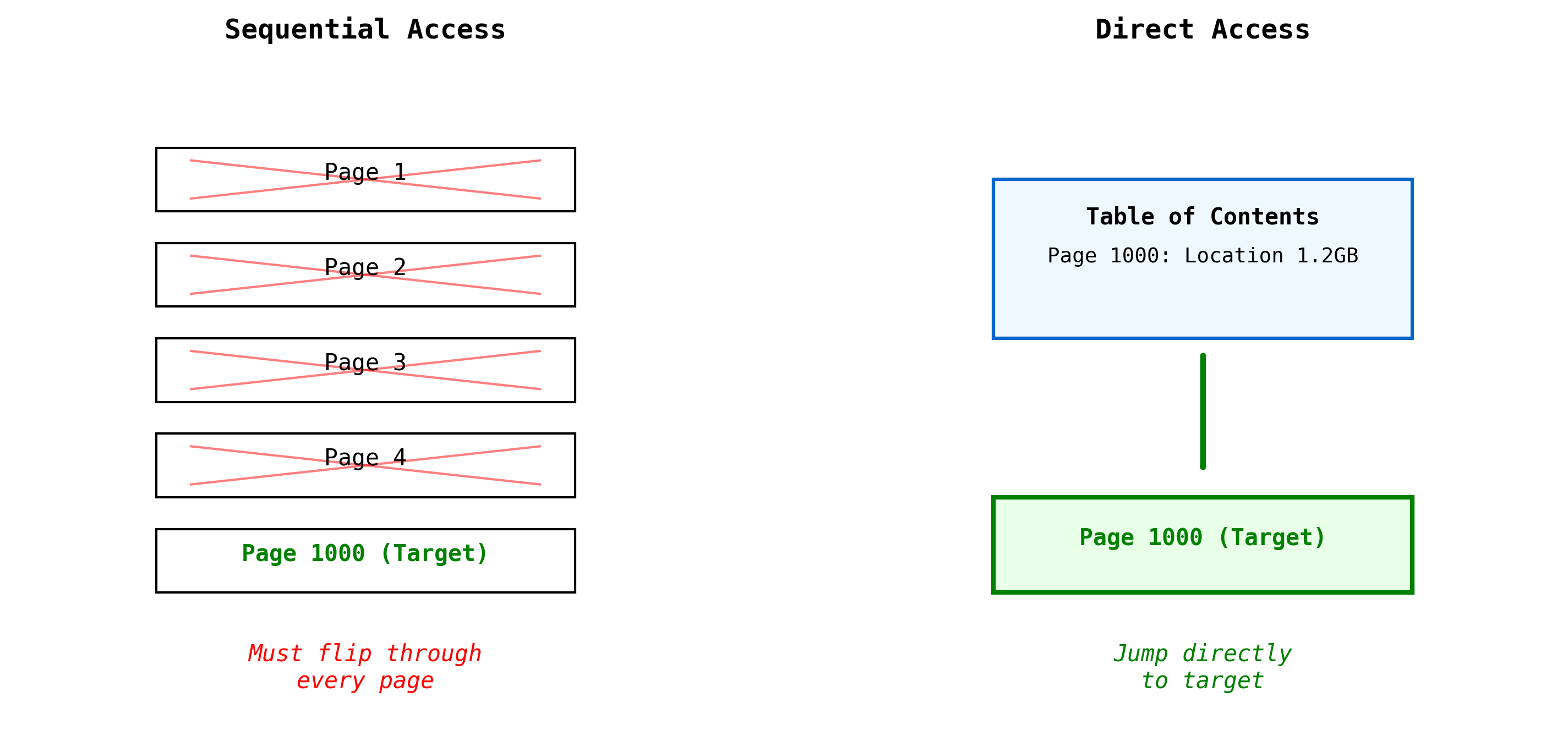
The Core Idea: A Table of Contents for Your Data
Imagine trying to find a specific chapter in a book without a table of contents; you'd have to flip through from the beginning. Lance builds that table of contents for your data. This is called a Repetition Index: a simple, compact array where each entry stores the starting byte offset of a corresponding data item. To find item
i
index[i]
Lance intelligently applies this concept using two primary strategies, chosen on a per-column basis.
Strategy 1: Full Zip Encoding for Fast Random Access
Best for: Large, unstructured data like images, audio clips, video frames, embeddings, and long documents.
When dealing with large binary objects (typically >256 bytes each), the highest priority is retrieving a specific item without reading anything extra. This is crucial for ML training (e.g., fetching random image samples) and interactive analysis.
How it Works: Full Zip Encoding uses the "table of contents" approach we discussed. It creates a Repetition Index that stores the exact byte offset for every single item. To get the 10,000th image, the system performs just two steps:
- Index Lookup: Reads the 10,000th entry in the index to find its starting address (e.g., byte ).45,210,481
- Direct Seek & Read: Jumps directly to that address in the file and reads only the data for that one image.
// Full Zip: Optimized for Random Access
Index: [0, 245KB, 483KB, ..., 1.2GB] // The "Table of Contents"
↓
Data: [img1][img2][img3]...[img1000000]
↑
Direct jump to any position. O(1) access.
This O(1) access means retrieving any item takes a constant amount of time, whether it's the first or the last. On S3, this translates to a single, efficient HTTP
Range
Strategy 2: Mini-Block Encoding for Fast Scans
Best for: Small, structured data like numbers (integers, floats), booleans, timestamps, and short strings (e.g., country codes, event types).
For these smaller data types, creating an index with an entry for every single value would be incredibly wasteful—the index could easily become larger than the data itself! Furthermore, the typical workload for this kind of data isn't random lookups, but fast, full-column scans as seen in analytical SQL queries (
SUM
AVG
GROUP BY
How it Works: Mini-Block Encoding groups values into small, highly optimized chunks (typically 4-8 KiB). Each mini-block is a self-contained unit that is compressed and arranged to be processed at extremely high speed by the CPU using SIMD instructions.
// Mini-Blocks: Optimized for Scans
Column: [Block 0 (4KB)][Block 1 (4KB)][Block 2 (4KB)]...
[vals 0-1023 ][vals 1024-2047]
To scan the column:
1. Read Block 0 -> Process 1024 values at once with SIMD.
2. Read Block 1 -> Process another 1024 values at once.
...
When a random lookup is needed, Lance reads one small block (a minor amount of read amplification) and decodes it. This is a deliberate trade-off: it sacrifices perfect O(1) access for this data type in exchange for blistering scan performance that rivals or exceeds Parquet.
By adaptively choosing between these two strategies for each column, Lance provides both fast random access for large,sparse reads and high-speed scanning for dense, analytical queries, all within a single file format.
5. Emerging Formats and Future Optimization Opportunities: Apache Vortex and Beyond
The innovation in storage formats is not limited to Lance. Other projects are pushing the boundaries of performance and compression, building on many of the same foundational ideas.
Apache Vortex: A Framework for Extreme Compression
While Lance focuses on optimizing data layout for access patterns, Apache Vortex (currently incubating) zooms in on the problem of data volume. It operates less like a single format and more like a framework for creating highly specialized, compressed columnar representations. Its core philosophy is that no single compression scheme is best for all data types and distributions.
- Composable Encodings: Vortex provides a rich library of powerful, type-aware compressors—like FSST for strings and ALP for integers—that can be chained together. For each column, a system can select the optimal pipeline of encodings to achieve maximum data reduction.
- SIMD-Native Decompression: All Vortex compressors are designed from the ground up for extreme decompression speed, using SIMD (Single Instruction, Multiple Data) instructions to process data at rates that can saturate modern memory bandwidth. The goal is to make decompression so fast that it's effectively "free," hiding behind I/O latency.
The Bleeding Edge: Specialized Compression and Learned Indexes
Beyond full-fledged formats, research into specialized techniques continues to influence the field:
-
Aggressive, CPU-Efficient Compression: Research projects like BTRBlocks demonstrate the power of combining highly specialized, type-aware compression with vectorized (SIMD) decompression. For cloud storage, this means less data to transfer and faster end-to-end query times, as the fast decompression prevents the CPU from becoming a bottleneck.
Inspired by this research, our engineers developed an experimental native storage format named StrawBoat. Its core philosophy is adaptive, data-driven compression:
- Block-by-Block Analysis: Instead of a one-size-fits-all approach, StrawBoat analyzes the data inside each block, examining its cardinality, distribution, and sortedness.
- Dynamic Algorithm Selection: Based on this analysis, it dynamically chooses the most effective and CPU-efficient algorithm for that specific block—whether it's Dictionary encoding, Frame of Reference (FOR), or Run-Length Encoding (RLE).
This strategy allows StrawBoat to maximize its compression ratio without sacrificing the high-speed decompression essential for analytical queries.
-
Learned Indexes & Data Layouts: Instead of using generic statistics like min/max, future formats may employ lightweight machine learning models to predict data distribution. This allows for more precise data skipping and even optimized data layouts, reducing the amount of data read from object storage in the first place.
-
I/O & Compute Overlap: The frontier of query engine design involves building schedulers and I/O layers (like Apache OpenDAL) that can perfectly overlap data fetching, decompression, and processing. This ensures that the massive throughput of cloud object stores is never wasted, keeping all parts of the system fully utilized.
6. Conclusion
The era of a one-size-fits-all storage format is drawing to a close. While Parquet remains a powerful and interoperable standard for traditional, scan-heavy analytics, the evolution of cloud infrastructure and data workloads has paved the way for a new generation of specialized formats. As we've seen, the question is no longer "Which format is best?" but "Which format is right for the job?"
The answer is a nuanced decision that rests on three critical pillars:
-
Workload and Use Case: The most important factor is the access pattern of your application. If your workload is dominated by large-scale, full-table scans for SQL-style analytics, Parquet's mature design is hard to beat. However, if you're building an AI application that requires fast, random lookups of multimodal data—like fetching individual images for model training or retrieving specific video frames—a format like Lance, designed for O(1) access, will deliver orders-of-magnitude better performance.
-
Library and Implementation Quality: A format's specification is only a blueprint; its real-world performance is dictated by the quality of its library implementation. A highly-optimized Rust library that leverages modern hardware features like SIMD and asynchronous I/O can make a well-designed format shine, while a naive implementation can leave performance on the table. The efficiency of the compression algorithms, the intelligence of the data layout, and the robustness of the reader are all critical.
-
Query Engine Integration: Finally, a storage format does not exist in a vacuum. Its performance is deeply intertwined with the query engine that reads it. A "storage-aware" query engine can amplify a format's strengths and mitigate its weaknesses. For example, an engine can use asynchronous prefetching and external metadata to overcome Parquet's chattiness on S3, or it can build schedulers that perfectly overlap I/O and compute to exploit the high throughput of object storage. The most powerful format is only as good as the engine that queries it.
Ultimately, the future of data architecture is a multi-format landscape. The challenge for data engineers is no longer to pick a single winner, but to build intelligent systems that can choose the right tool for each job, leveraging the unique strengths of each format to build faster, more efficient, and more capable data platforms.
7. References
- Lance Research Paper: "Lance: Efficient Random Access in Columnar Storage through Adaptive Structural Encodings"
- Procella Research Paper: "Procella: Unifying Serving and Analytical Data at YouTube"
- BTRBlocks Research Paper: "BTRBlocks: Efficient Columnar Storage for High-Performance Data Analytics"
- Apache OpenDAL Official Website: A data access layer that allows unified access to various storage services.
- Apache Arrow Rust (contains parquet-rs): The official Rust implementation of Apache Arrow and Parquet.
- Apache Parquet Format Specification: The official documentation for the Parquet file format.
- Apache Arrow Official Website: The in-memory columnar format that underpins many modern data systems.
- Vortex (Incubating) Documentation: The official documentation for the emerging Vortex compression framework.
8. Resources
- StrawBoat GitHub Repository. Inspired by BTRBlocks, designed for adaptive, high-performance compression.
- GitHub Repository
- Community Slack
- Book a Demo with us
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

