


From $1M+ to Zero: How We Eliminated Our AWS Lambda Bill in the S3 Data Lake with Databend
Our AWS bill for a single data pipeline quietly crept past $1,000,000 a month.
This wasn't due to a rogue process or a sudden, unexpected spike in traffic. This was the predictable, slow-burning result of following a celebrated industry 'best practice': the serverless S3 data lake. The blueprint is simple and seductive: use AWS Lambda to compact streaming events from kafka/flink and write them to S3, then query them with Athena. It promises infinite scalability and pay-as-you-go savings.
For us, it delivered the opposite. At high volumes, this pattern became a financial and operational disaster. It created a data swamp with billions of tiny, unmanageable files, crippled our analytics with slow and failing queries, and locked us into a seven-figure monthly bill for an architecture that was fundamentally broken.
Our key expectation is to stop managing or compacting small files through AWS lambda and adopt a platform that does it automatically and transparently. This led us to Databend, which ingests our data stream and optimizes AWS S3 data lake in a single step, which eliminated the small-file problem at its source.
The architecture that looked perfect—until the bill arrived
We did what the playbooks say. Events from our network gateways flowed into Kafka (steady 10k+ TPS). Flink cleaned and wrote to S3 “in real time.” We laid out the lake as user_id/date. A Lambda job merged small files. Analysts queried with Athena. On paper, it was make sense as it is serverless and pay-as-you-go.
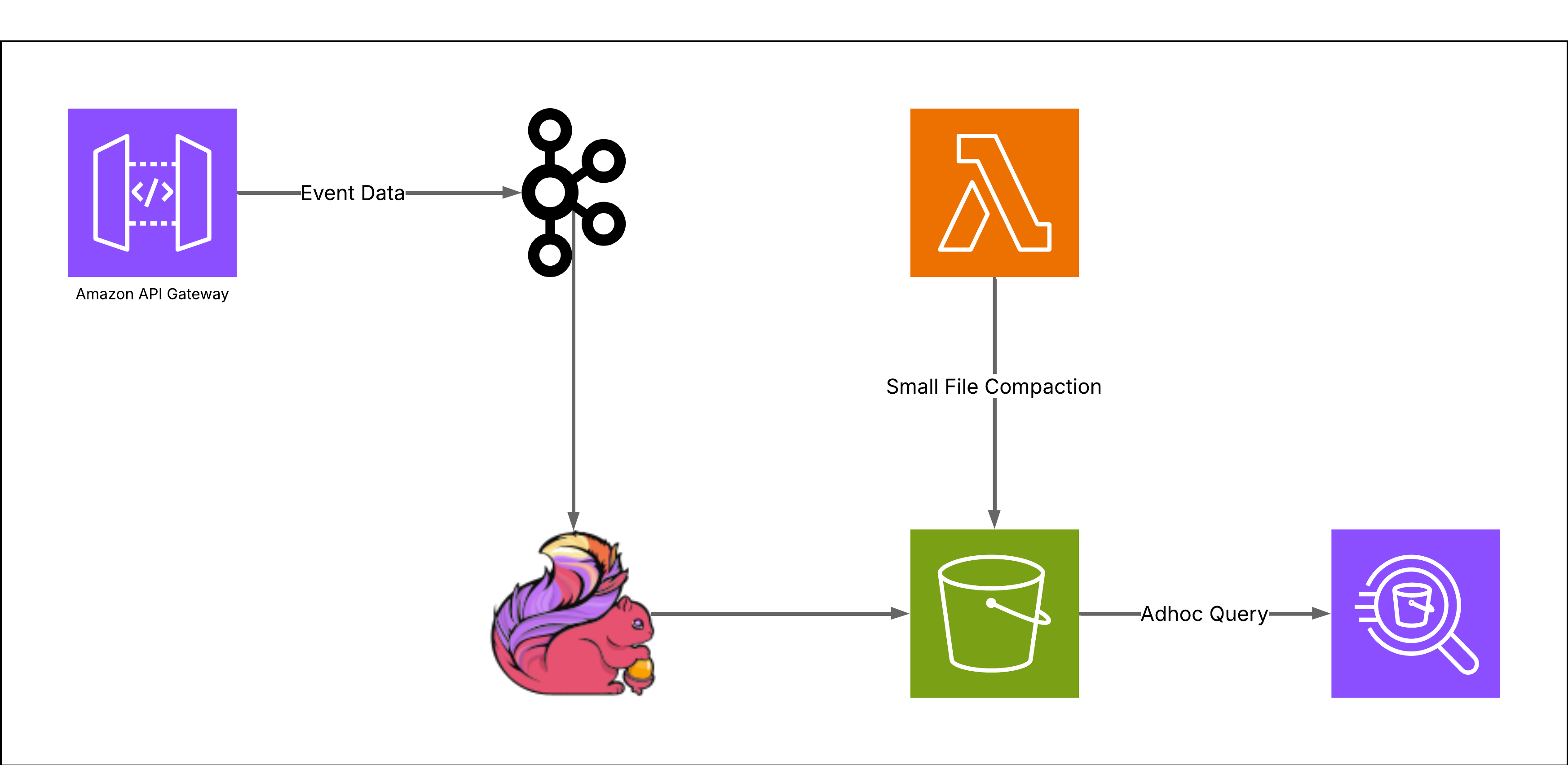
In practice, our scale changed the rules:
- 1B+ unique user_ids.
- Hundreds of billions to trillions of S3 objects.
- A constant stream of tiny files, faster than we could merge them.
Where the bill crept up
If you guessed that storing trillions of S3 objects or running queries was our biggest expense, you'd be mistaken. Here’s the real breakdown:
- Kafka and Flink: These are the workhorses of our ingestion system. Their costs are significant but predictable. They scale directly with the volume of events we process, not with how much data we store.
- S3 Storage & Requests: Storing data in S3 is cheap. The real cost comes from interacting with it. With billions of unique users, our partitioning strategy created a "small file problem"—trillions of tiny objects. Every time we list, read, or write a file, it generates an S3 request fee. These fees add up.user_id
- AWS Athena: Surprisingly, our query costs remained quite low. Our Lambda functions worked hard to compact and organize the data, which meant our analysts could run laser-focused queries. They typically scanned only the specific partitions they needed, keeping Athena bills minimal. We intentionally avoided queries across other dimensions (like non-user-id or timestamp-based analytics) because scanning trillions of small files would have been both slow and expensive.user_id
- AWS Lambda (The Dominant Cost): This was the source of a $1M/month bill. The Lambda functions designed to solve our small file problem became our single largest operating expense.
Why Did Lambda Cost So Much?
The cost wasn't in the complexity of the code, but in the sheer volume of work.
- Massive Fan-Out: Our architecture triggered a Lambda function for every single partition that needed merging. With data pouring in 24/7 across billions of users, this meant a constant, massive storm of Lambda invocations.
- Death by a Trillion Cuts: Each Lambda invocation performed a series of costly operations. It had to list all the tiny files in a partition, read each one (S3 GET), process the data, and write a new, larger file (S3 PUT). This read-many, write-one pattern multiplied our S3 request costs, and the compute time for each function added up.
- Archival Overhead: Even moving compacted files to cheaper cold storage was expensive. Lifecycle policies charge on a per-object basis, and transitioning billions of individual objects, even small ones, incurred huge costs. The core lesson was clear: Our pipeline's cost wasn't driven by data volume, but by object count. Athena was cheap because it scanned a few, large objects. Lambda was expensive because it had to manage trillions of tiny ones.
Why Not Just "Fix" It with Compaction?
The Obvious Idea: A common solution is to run a separate process (e.g., using AWS Glue or a scheduled EMR job) to periodically compact small files into larger ones.
The Reality Check: At our scale, this approach becomes impractical. We're generating more than 10,000 objects in S3 every second. This volume is extremely challenging for analysts or data engineers to handle with custom services built from scratch using AWS clients or EMR.
The complexity goes beyond just scheduling compaction jobs—you need real-time coordination between ingestion and compaction, sophisticated error handling for S3 throttling, state management to track processed files, and monitoring for a system that should ideally be invisible. The engineering effort alone would be substantial, and we'd end up maintaining yet another complex distributed system. This was exactly what we wanted to avoid.
What We Really Needed: A one-stop solution that could handle ingestion, compaction, updates, and queries all within a single data warehouse—with minimal on-premise maintenance. We didn't want to become experts in managing yet another complex distributed system.
Migrating to Databend: A Practical Approach
When we evaluated Databend for our logging pipeline, the migration path turned out to be refreshingly straightforward. Unlike many data warehouse migrations that require extensive ETL rewrites, Databend's architecture aligned naturally with our existing S3-based workflow.
The Migration Story
Our existing pipeline already wrote Parquet files to S3, which became our biggest advantage. Instead of rebuilding the entire ingestion layer, we simply:
- Pointed our Flink jobs to an S3 stage that Databend could access
- Set up automatic idempotent COPY INTO commands to pull data from the stage into Databend tables
- Let Databend handle the rest The engineering effort was minimal—we're talking days, not months. No complex connectors, no proprietary formats, no vendor lock-in concerns. If your data is already in S3 (in Parquet, CSV, or JSON), you're already 80% of the way there.
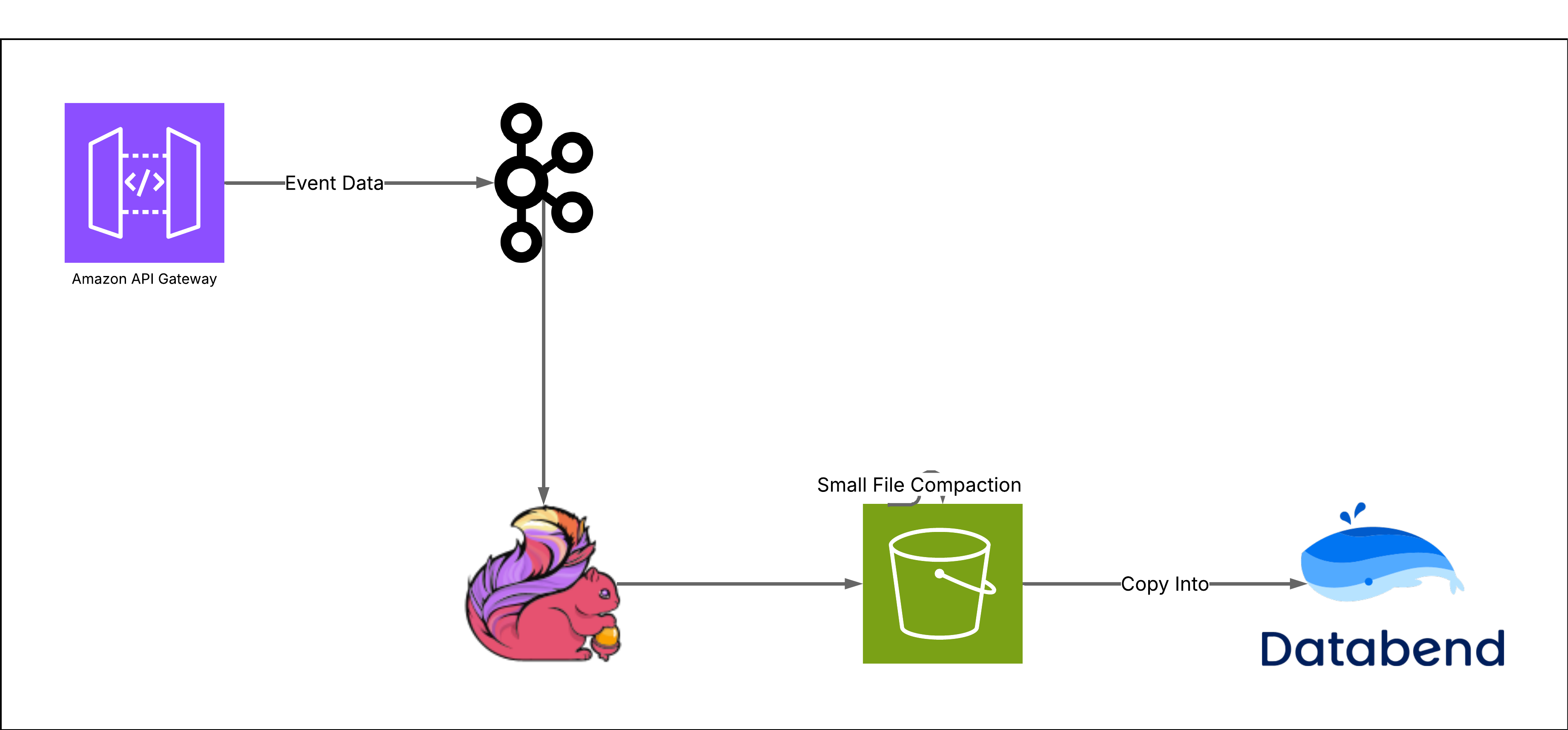
Our Logging Architecture in Databend
We kept things simple with a single wide table for all gateway logs. This table handles our sustained write load of 100,000+ rows per second without breaking a sweat. We run 5 write nodes to handle the ingestion, which gives us both redundancy and consistent performance.
The real elegance comes from Databend's storage-compute separation. Once data lands in the table, it's immediately available to any number of independent query warehouses. Our analysts can spin up dedicated compute clusters for their workloads without impacting the write path. Need more query power for a complex analysis? Scale up. Done with the heavy lifting? Scale down. The data stays put while compute resources flex with demand.
The Outcome of Our Migration
The New Cost Structure
After decommissioning the Lambda pipeline, our cost model changed fundamentally. The unpredictable, seven-figure monthly bill for serverless compute and API calls was replaced by:
- Predictable EC2 costs for a 5-node Databend cluster, which runs around $3,000/month.
- Standard S3 storage costs, but with a significant reduction in S3 API request fees (fewer LIST and PUT operations).
This change resulted in a TCO reduction of over 90% for this data pipeline, freeing up both budget and engineering resources that were previously dedicated to managing the old system.
Operational Improvements
Beyond the cost savings, the daily work for our engineering team became much simpler:
- From Reactive to Proactive: The constant stream of alerts from failing Lambda functions and S3 API throttling disappeared. This freed the team from a reactive, firefighting mode and allowed us to focus on proactive improvements.
- Improved Data Accessibility: With query times dropping from minutes to under 15 seconds, our analysts could finally explore data interactively. This fostered a more data-curious culture, as the barrier to asking new questions was significantly lowered.
A Look at the Core Architectural Principles
The success of this migration wasn't about a single feature, but rather a shift to a few fundamental principles that were a better fit for our workload:
-
Consolidate the write path: Previously, ingestion and compaction ran as separate, asynchronous jobs—creating excess state, API churn, and lots of small files. Now they happen in one transactional operation: we ingest, organize (sort/cluster), and compact as part of a single write. This prevents small files at the source and simplifies operations.
-
Layered pruning instead of brute-force scans: We moved from listing millions of S3 objects to pruning at multiple levels. The planner uses partitioning, micro-partitions, min/max statistics (zone maps), indexes, and bloom filters to skip irrelevant blocks. I/O becomes proportional to what a query needs, not to table size.
-
Decouple compute for reads and writes: Heavy analytics no longer slow ingestion. With true storage–compute separation, ingestion runs on its own pool while analysts scale query clusters independently. This isolates workloads, improves throughput, and keeps latency predictable.
Key Takeaways from Our Journey
This project taught us a few valuable lessons that have stuck with us:
- Serverless Isn't a Silver Bullet. It's a powerful tool, but for stateful, high-throughput data processing, the operational overhead can sometimes outweigh the benefits. Always evaluate the right tool for the specific job.
- Total Cost of Ownership is Deceptive. We learned the hard way that optimizing one part of a system (like our cheap Athena queries) can create massive hidden costs elsewhere. You have to look at the entire, end-to-end workflow.
- Engineers Need Good Abstractions. The moment we could stop thinking about files and start thinking in terms of tables, our productivity soared. A good data platform abstracts away the low-level plumbing.
Is This Story Familiar?
If you're reading this and nodding along, here are a few questions to ask about your own systems:
- Where does your team spend its time? Are they building business logic or managing the infrastructure that moves data around?
- What do your cloud bills really say? Are API costs a significant line item? That's often a sign of an inefficient architecture.
- Can your team explore data freely? Or are they held back by performance or budget bottlenecks and fear of breaking the system?
Resources
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

